Predicting Performance for Natural Language Processing Tasks
This is a post regarding our paper that will be presented at ACL 2020. tl;dr: You can use previously published results to get an estimation of the performance on a new experiment, before running it! We describe NLP experiments with a set of interpretable features, and train prediction models which are actually pretty good at producing such estimations, and show how they can be useful in various scenarios.
Scenarios that you might meet
Scenario 1: You develop NLP tools for a company, and your boss asks you to build a machine translation system for a new language pair you don't have support for yet. You pop by WMT to check out what the latest advances in MT are, and this [matrix of results](http://matrix.statmt.org/) gives you quality numbers for translation in Czech--German, German--French, and English to Finnish, Gujarati, Kazakh. Some systems are very good with BLEU scores over 40, others are pretty bad (English--Kazakh BLEU: 11.1).
Can you answer your boss's questions: How good will your English-Punjabi MT system be? How much data will you need (remember, data=$$$) to build a Hausa--Igbo MT system that will get over 40 BLEU?
Scenario 2: You want to compare word embedding alignment methods, so that you can choose the one that performs better on the language pairs that you care about. If you had results in the language pairs shown in the following table, which method would you choose for a new language pair e.g. Portuguese--Russian?

Scenario 3: You are a NLP grad student and you have a new research idea that you think could lead to improvements in morphological inflection and language generation for morphologically-rich languages. You visit the [SIGMORPHON website](https://sigmorphon.github.io/sharedtasks/) and the shared tasks from the last 2 years, which combined provide a train, dev, and test data on more than 100 languages! Where do you start? Research happens in an iterative manner, you make little changes to your models and observe the quality changes on dev outputs -- you cannot possibly do your model development on 100 languages at once, this would take forever! How can you choose which languages to initially develop systems on, so that you can be at least somewhat sure that your findings will also generalize on all other languages?
How can we estimate the performance of an experiment without actually running a system?
In this work we build a sort-of meta-model, which tries to predict the performance of an NLP experiment, given a few features that describe the experimental setting. We use simple features to describe:
- - the dataset(s) used,
- - the language(s),
- - the training procedure and the model
Main Results: Turns out that even with these simple features and a gradient boosted decision trees algorithm over them one can do a good job of predicting the performance of a NLP experiment.
We evaluated our approach on 9 NLP tasks (including machine translation, parsing, tagging, lexicon induction). Our model (NLPERF) consistently outperforms naïve baselines such using the mean performance across all experiments, or across the same source/target/transfer language, or across the same model as the baseline’s predictions (the table shows the root mean square error of the predictions, so lower is better).
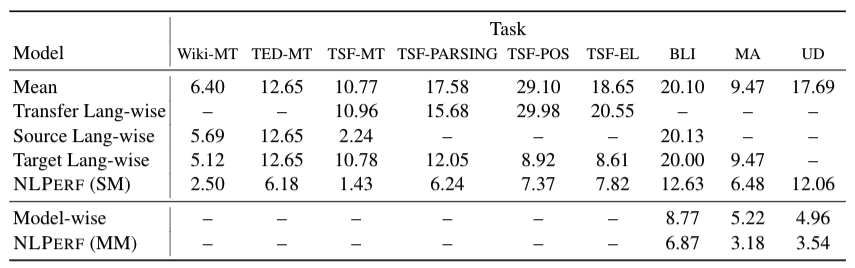
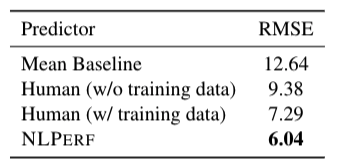
Human Evaluation: We also performed a small case study where we asked machine translation experts to predict the performance (in terms of BLEU) of an experiment, given the same features that our model uses. Results are shown in the table on the right, which lead to two main observations:
1. Previous experiments (in this case, experiments on other languages) can inform the experts about the potential outcome of a new experiments (e.g., if you know the achievable BLEU score in English-Spanish, you can kinda estimate the achievable BLEU score in English-Portuguese under similar data and model conditions). This means that this task is indeed learnable (humans can perform it!) and the the features that describe an NLP experiment can be used to learn this task.
2. To reinforce the above observation, our model does outperform MT experts on this task, even though it is quite simple and it does not use any complicated features!
Implications
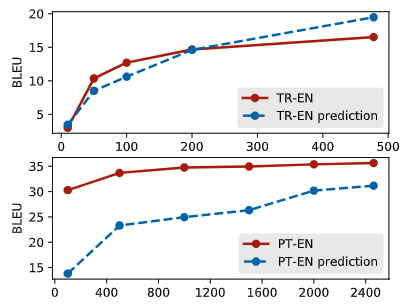
Having access to such a NLP experiment performance predictor leads to several cool applications.Feature Extrapolation: The first is the straightforward one: you can use it to get a performance estimation for datasets with various data sizes. We show examples in the following figure: we can do a very good job in predicting Turkish-English translation BLEU scores under different data conditions. The predictions are less accurate in Portuguese-English, though (although, the very high BLEU scores in Portuguese-English are a bit of an outlier compared to other-languages-to-English translation in low-resource settings).
Representative Datasets: Having access to a good predictor can also help us decide which datasets we should be testing on. Since what we care about is generalization across languages, domains, and datasets, and assuming that evaluating our NLP models on all possible languages and domains is infeasible, we would want to at least evaluate our models on the datasets that allow to draw the more trustworthy conclusions about such generalizations.
In our work, we showed how one can use a predictor to actually find which are these datasets/languages that we should be evaluating our models on. Our assumption is that the subset of datasets that leads to the best predictions on all other datasets.
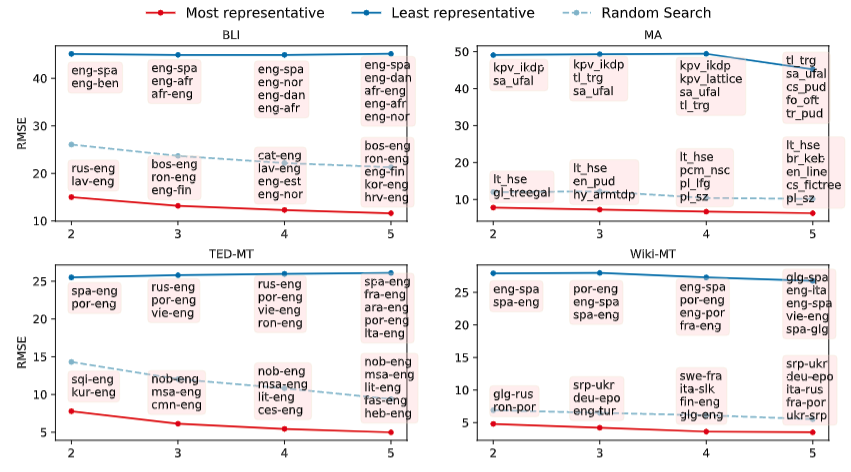
Using a beam-search like approach over the already published experimental results, we find the most representative (as well as the least representative!) dataset subsets. Unsurprisingly, the least representative ones include only typologically similar languages e.g. in machine translation into English on TED data (TED-MT in the figure) Spanish, French, Portuguese, Italian, and Arabic makes up the worst subset of 5 source languages for predicting the BLEU scores on all others. (They are all high-resource language pairs too, which further exarcebates the issue).
In the BLI task, the least representative language pairs are actually the ones that were most typically used by academic works for reporting results before the larger and more multilingual collection of MUSE dictionaries was available!
Another cool finding is that we can actually predict the performance of a new model on several datasets using only a few results (e.g. 1,2, or 3) on a subset of datasets. For the majority of the models in the Universal Dependencies dependency parsing shared task we only need results on one or two treebanks (plus the results of all other models, of course) to do better than baseline predictions.
Future Work
This work is but the first step and the utility of such predictors on real-world scenarios is still to be proven. Nevertheless, this research direction opens up a slew of possibilities.
On the modeling side, perhaps more expressive model features and a better featurization of an NLP/ML experiment can lead to even more accurate predictions.
On the application side, maybe we will be able to estimate not only performance but also other metrics such as downstream utility or expected improvements, depending on the tasks.
At the very least, we hope we will be able to get a better grasp of the quality of NLP tools across different languages and domains, without relying on expensive experimentation (even though we wholeheartedly wish that it was indeed possible to experiment on all languages and domains at once!) and hyper-parameter tuning.
Antonios Anastasopoulos
Assistant Professor
I work on multilingual models, machine translation, speech recognition, and NLP for under-served languages.