Abstract
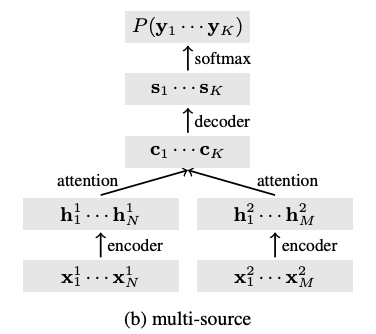
Recently proposed data collection frameworks for endangered language documentation aim not only to collect speech in the language of interest, but also to collect translations into a highresource language that will render the collected resource interpretable. We focus on this scenario and explore whether we can improve transcription quality under these extremely lowresource settings with the assistance of text translations. We present a neural multi-source model and evaluate several variations of it on three low-resource datasets. We find that our multi-source model with shared attention outperforms the baselines, reducing transcription character error rate by up to 12.3%.
Type
Publication
Proc. Interspeech 2018