CS 310 HW3: Ack! Cell, Tree, DAG
- Deadlines
- Milestone Deadline: 11:59pm Thursday 11/10/2016
- Final Deadline: 11:59pm Thursday 11/17/2016
- Submit to Blackboard
- Approximately 8.75% of total grade
- Code for this assignment is here: distrib-hw3.zip
- Milestone Test Cases: HW3MilestoneTests.java

- Final Test Cases
- CellTests.java (48 tests, identical to tests in
HW3MilestoneTests) - DAGTests.java (62 tests)
- SpreadsheetTests.java (75 tests)
- HW3FinalTests.java (185 total tests, runs all tests in
CellTests, DAGTests, SpreadsheetTests)
- CellTests.java (48 tests, identical to tests in
CHANGELOG:
- Mon Nov 14 10:34:04 EST 2016
- A section on Efficient add implementation in
DAGhas been added to guide implementations away from making copies of maps and towards incremental modification of DAGs. - Fri Nov 11 15:33:58 EST 2016
- Final test cases have been linked to the top of the spec. There
are 3 test files for
CellTests, DAGTests, SpreadsheetTestswhich test individual classes.HW3FinalTestssimply runs the tests in each of these files; it may not work with IDEs such as DrJava but eases the task of running multiple tests on the command line. There are 185 total tests spread across the 3 main unit test files. - Tue Nov 8 11:31:25 EST 2016
- Clarification that
displayString()for number cells should return a string with 1 decimal place of accuracy for the number; see post @602. - Wed Nov 2 09:11:12 EDT 2016
- The complexity of
Cell.getUpstreamIDs()isO(T)whereTis the size of the formula tree. The complexity was incorrectly stated asO(1)in the initial release of the spec. See @579 for discussion.Docstrings for the
Cellclass previously mentioned the methodupdateFormulaValue()which has been corrected toupdateValue(). - Tue Nov 1 11:46:23 EDT 2016
- Milestone tests are now available for HW3 linked at the top of
the HW3 spec.
Updated the documentation string associated with
Cellto clarify thatCell.make(contents)may raise exceptions for invalid input such as "1 ++ 2"; =FNode.parseFormulaString(s)raisesRuntimeExceptionon encountering such bad syntax.Added an example diagram parsing formulas in the Formula Parsing section to clarify what these look like and how they relate to the text layout of the parsed formula trees.
- Mon Oct 31 16:44:43 EDT 2016
- Final Automated Tests will account for 45% of the overall grade; they were initially listed incorrectly as worth 40%.
- Fri Oct 28 10:12:52 EDT 2016
- The due date for Milestones is Thursday 11/10/2016. It was originally incorrectly stated as Monday 11/7/2016.
Table of Contents
- 1. Overview
- 2. Project Files
- 3. Using
formula.jar - 4. Class Architecture
- 5. Cells and Formulas
- 6. DAG: Directed Acyclic Graphs for Circular Reference Detection
- 7. Spreadsheet: Tying it all Together
- 8. Grading
- 9. Final Manual Inspection Criteria
- 9.1.
CellDesign and Documentation (10%) - 9.2.
CellRecursive Function Elegance (10%) - 9.3.
DAGMethod Complexity and Elegance (10%) - 9.4.
SpreadsheetSave/Load Functionality (5%) - 9.5.
SpreadsheetCell ID Verification (5%) - 9.6.
SpreadsheetsetCell()anddeleteCell()Notifications (5%) - 9.7. Code Readability (5%)
- 9.1.
- 10. Setup and Submission
1 Overview
This project will be the most involved of the semester so plan your time accordingly. There is not a tremendous amount of code to write but it will involve some careful thought. The end product will tie together several topics and show how data structures can be employed to produce (somewhat) practical software.
Most CS students should have gained casual familiarity with spreadsheets through use of software such as Microsoft Excel. In fact, many non-CS folks in the working world experience a limited form programming through spreadsheets which can become quite complex and in some cases are Turing complete.
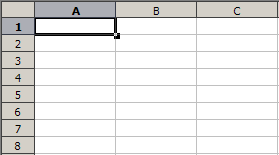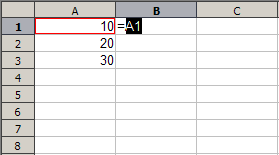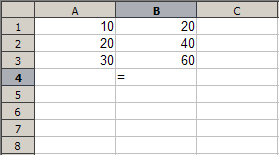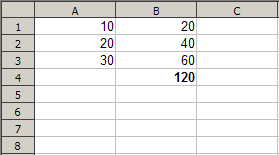
Figure 1: Basic spreadsheet use with data and formulas
For those with little experience, spreadsheets are a rectangular grid of cells into which data is entered. The data may be raw numbers, strings, or formulas which most frequently perform arithmetic operations on the contents of other cells to produce a new value. The main feature of interest for spreadsheet implementation is that formulas automatically update when the cells on which they depend change contents. For example, below is a simple display of a spreadsheet with contents and values.
ID | Value | Contents
-------+--------+---------------
A1 | 22.0 | '22'
B1 | 33.0 | '33'
C2 | 55.0 | '=A1 + B1'
The spreadsheet might actually display as follows.
| | A | B | C | |---+------+------+------| | 1 | 22.0 | 33.0 | | | 2 | | | 55.0 | | 3 | | | |
However, this display obscures the fact that the cell C2 is in fact
a formula based on cells A1 and B1. Changing the contents of
either of these cells (e.g. setting B1 to 5) automatically updates
the value that appears in C2. Example:
set B1 5
ID | Value | Contents
-------+--------+---------------
A1 | 22.0 | '22'
B1 | 5.0 | '5'
C2 | 27.0 | '=A1 + B1'
Notice that the formula in C2 has not changed but its value reflects
the change. Formulas can be chained together as seen here where a new
formula uses the value of another formula in its computation
set A3 =B1 / (C2-2)
ID | Value | Contents
-------+--------+---------------
A1 | 22.0 | '22'
A3 | 0.2 | '=B1 / (C2-2)'
B1 | 5.0 | '5'
C2 | 27.0 | '=A1+B1'
Changes to the upstream cells are propagated to all downstream cells dependent on their values. The following dependencies exist in the spreadsheet above:
Upstream Links: A3 : [B1, C2] // cells on which A3 depends C2 : [A1, B1] // cells on which C2 depens Downstream Links: A1 : [C2] // cells A1 should notify when it changes B1 : [A3, C2] // cells B1 should notify when it changes C2 : [A3] // cells C2 should notify when it changes
The links mentioned above are created only by cells with formulas and dictate where changes must propagate. For example:
- Setting
A1to a new value should notifyC2which depends on it. - A change in
C2should in turn notifyA3to recalculate. A3has no downstream links so no further notification is required- Setting
B1to a new value should notify bothA3andC2 - The subsequent change to
C2should re-notifyA3to recalculate again.
This chain of messages allows formulas to preserve relationships among
cells as demonstrated below in which a change to A1 changes the
values of A3 and C2.
set A1 1
ID | Value | Contents
-------+--------+---------------
A1 | 1.0 | '1'
A3 | 1.3 | '=B1 / (C2-2)'
B1 | 5.0 | '5'
C2 | 6.0 | '=A1+B1'
If one of the cells involved in a formula is blank or non-numeric, all dependent formulas produce errors.
set A1 hello
ID | Value | Contents
-------+--------+---------------
A1 | hello | 'hello'
A3 | ERROR | '=B1 / (C2-2)'
B1 | 5.0 | '5'
C2 | ERROR | '=A1+B1'
set A1 1
ID | Value | Contents
-------+--------+---------------
A1 | 1.0 | '1'
A3 | 1.3 | '=B1 / (C2-2)'
B1 | 5.0 | '5'
C2 | 6.0 | '=A1+B1'
Finally, formulas may depend on one another so long as circular references are not created. A circular reference would make the process of notify other cells of updates endless.
set A1 =A3+5 Could not set cell A1 to =A3+5: Cell A1 with formula '=A3+5' creates cycle: [A1, A3, C2, A1]
The above attempt to change A1 results in a cycle of references that
would roughly read:
ID | Value | Contents
-------+--------+---------------
A1 | 1.0 | '=A3+5' // depends on A3
A3 | 1.3 | '=B1 / (C2-2)' // depends on C2
C2 | 6.0 | '=A1+B1' // depends on A1 - cycle
While some spreadsheet applications allow circular reference, detecting and preventing them from occurring will be a primary part of this project.
2 Project Files
The following files are relevant to the HW. When submitting, place
them in your HW Directory, zip that directory and submit. Always
submit a zip file not tar.gz, not bzip, not 7zip, just vanilla zip
files. For additional instructions see Setup and Submission.
| File | State | Notes |
|---|---|---|
| Cell.java | Create | Data stored in a spreadsheet, responsible for formula evaluation. |
| You may create subclasses of it for strings, numbers, and formulas | ||
| DAG.java | Create | Class representing Directed Acyclic Graphs to detect circular references in formulas. |
| SpreadSheet.java | Create | Basic underlying model of a spreadsheet, ties together Cells and a DAG |
| TokenType.java | Provided | Enumeration of the types of FNodes that occur in formula trees |
| FNode.java | Provided | Element of binary formula trees, provides formula parsing but not evaluation |
| AckCell.java | Provided | Interactive application for spreadsheets. No modification needed. |
| formula.jar | Provided | Back-end parsing functionality used by FNode |
| DAGDemo.java | Provided | Shows basic usage of the DAG class and provides the toSet(..) utility method |
| ID.txt | Edit | Identifying information |
3 Using formula.jar
A parsing library is provided to ease the task of reading cell formula
strings. This is the formula.jar file. Most of the compilation you
will do will need to add this to the class path. Doing so on the
command line is identical to how one incorporates the
junit-cs310.jar file.
> javac -cp junit-cs310.jar:formula.jar:. FNode.java
> java -cp junit-cs310.jar:formula.jar:. FNode
usage: java -jar formula.jar FNode 'formula to interpret'
Example: java -jar formula.jar FNode '=A1 + -5.23 *(2+3+A4) / ZD11'
> java -cp junit-cs310.jar:formula.jar:. FNode '=1 + 2*4 / (7+11)'
+
1
/
*
2
4
+
7
11
> javac Cell.java
./FNode.java:1: error: package org.antlr.v4.runtime does not exist
import org.antlr.v4.runtime.*;
...
...
38 errors
# Forgot to include formula.jar
> javac -cp formula.jar:. Cell.java
> ls Cell.class
Cell.class
In DrJava, you will need to to add formula.jar to the classpath
where DrJava looks for classes under the Edit -> Preferences dialog.
This will enable compilation and use of the Cell and Spreadsheet
classes in the interactive loop.
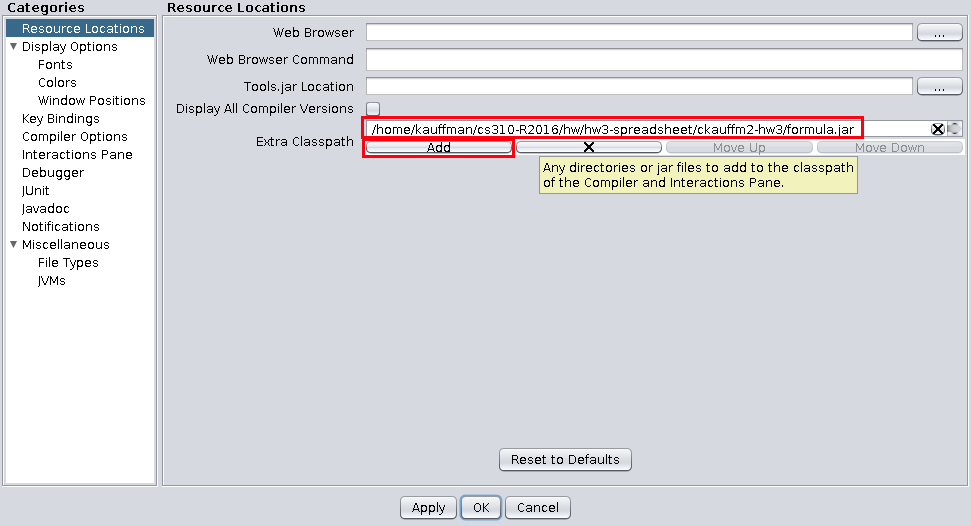
Figure 2: Add formula.jar to the classpath to enable DrJava to use it in the interactive loop.
Other IDEs should consult the documentation on how to add a JAR to their classpath.
4 Class Architecture
The basic architecture of the spreadsheet application is based on two
support classes (Cell and DAG) along with a unifying model
(Spreadsheet) and a driver which takes user commands
(AckCell).
A support class called FNode is also provided which will parse a
string representing a formula and create a binary expression tree.
Cells will walk this tree to evaluate formulas.
Each class is outlined in the following sections.
4.1 Cell
// Spreadsheet Cells can be one of three different kinds:
// - Formulas always start with the = sign. If the 0th character in
// contents is a '=', use the method
// FNode root = FNode.parseFormulaString(contents);
// to create a formula tree of FNodes for later use.
// - Numbers can be parsed as doubles using the
// Double.parseDouble(contents) method.
// - Strings are anything else aside from Formulas and Numbers and
// store only the contents given.
//
// Cells are largely immutable: once the contents of a cell are set,
// they do not change except to reflect movement of upstream dependent
// cells in a formula. The value of a formula cell may change after
// if values change in its dependent cells. To make changes in a
// spreadsheet, one will typically create a new Cell with different
// contents using the method
// newCell = Cell.make(contents);
//
// This class may contain nested static subclasses to implement the
// differnt kinds of cells.
public class Cell {
// Factory method to create cells with the given contents linked to
// the given spreadsheet. The method is static so that one invokes
// it with:
//
// Cell c = Cell.make("=A21*2");
//
// The return value may be a subclass of Cell which is not possible
// with constructors. Call trim() on the contents string to remove
// whitespace at the beginning and end. If the contents is null or
// empty, return null. If contents is not valid, a RuntimeException
// is generated; this may happen if the contents is a formula that
// cannot be parsed by FNode.parseFormulaString(contents) which
// raises RuntimeExceptions for invalid syntax such as "=1 ++ 2"
//
// If the cell is a formula, it is not possible to evaluate its
// formula during Cell.make() as other references to other cells
// cannot be resolved. The formula can only be reliably evaluated
// after a call to cell.updateValue(cellMap) is made later. Until
// that time the cell should be in the ERROR state with
// cell.isError() == true and displayString() == "ERROR" and
// cell.numberValue() == null.
public static Cell make(String contents);
// Return the kind of the cell which is one of "string", "number",
// or "formula".
public String kind();
// Returns whether the cell is currently in an error state. Cells
// with kind() "string" and "number" are never in error. Formula
// cells are in error and show ERROR if their formula involves cells
// which are blank or have kind "string" and therefore cannot be
// used to calculate the value of the cell.
public boolean isError();
// Produce a string to display the contents of the cell. For kind()
// "string", this method returns the original contents of the
// cell. For kind "number", show the numeric value of the cell with
// 1 decimal point of accuracy. For formula cells which are in
// error, return the string "ERROR". Formula cells which are not in
// error return a string of their numeric value with 1 decimal digit
// of accuracy which is easiest to produce with the String.format()
// method.
//
// Target Complexity: O(1)
// Avoid repeated formula evaluation by traversing the formula tree
// only in updateValue()
public String displayString();
// Return the numeric value of this cell. If the cell is kind
// "number", this is the double value of its contents. For kind
// "formula", it is the evaluated value of the formula. For kind
// "string" return null.
//
// Target Complexity: O(1)
// Avoid repeated formula evaluation by traversing the formula tree
// only in updateValue()
public Double numberValue();
// Return the raw contents of the cell. For kind() "number" and
// "string", this is the original contents entered into the cell.
// For kind() "formula", this is the text of the formula.
//
// Target Complexity: O(1)
public String contents();
// Update the value of the cell value. If the cell is not a formula
// (string and number), do nothing. Formulas should re-evaluate the
// stored formula tree to determine a numeric value. This method
// may be called when the cell is initially created to give it a
// numeric value in which case an empty map should be used.
// Whenever an upstream cell changes value, the housing spreadsheet
// will call this method to recompute the numeric value to reflect
// the change. This method should not raise any exceptions if there
// are problems evaluating the formula due to other unusable cells.
// It should set the state of this cell to be in error so that a
// call to isError() returns true. If the cell formula is
// successfully evaluated, isError() should return false.
//
// Target Complexity:
// O(1) for "number" and "string" cells
// O(T) for "formula" nodes where T is the number of nodes in the
// formula tree
public void updateValue(Map<String,Cell> cellMap);
// A simple class to reflect problems evaluating a formula tree.
public static class EvalFormulaException extends RuntimeException{
public EvalFormulaException(String msg);
}
// Recursively evaluate the formula tree rooted at the given
// node. Return the computed value. Use the given map to retrieve
// the number value of cells which appear in the formula. If any
// cell ID in the formula is unusable (blank, error, string), this
// method raises an EvalFormulaException.
//
// This method is public and static to allow for testing independent
// of any individual cell but should be used in the
// updateValue() method to allow individual cells to compute
// their formula values.
//
// Inspect the FNode and TokenType classes to gain insight into what
// information is available in FNodes to inspect during the
// post-order traversal for evaluation.
//
// Target Complexity: O(T)
// T: the number of nodes in the formula tree
public static Double evalFormulaTree(FNode node, Map<String,Cell> cellMap);
// Return a set of upstream cells from this cell. Cells of kind
// "string" and "number" return an empty set. Formula cells are
// dependent on the contents of any cell whose ID appears in the
// formula and returns all such ids in a set. For formula cells,
// this method should call a recursive helper method to traverse the
// formula tree and accumulate a set of ids in the formula tree.
//
// Target Complexity: O(T)
// T: the number of nodes in the formula tree
public Set<String> getUpstreamIDs();
}
4.2 DAG
// Model a Directed Acyclic Graph (DAG) which allows nodes (vertices)
// to be specified by name as strings and added to the DAG by
// specifiying their upstream dependencies as a set of string IDs.
// Attempting to introduce a cycle causes an exception to be thrown.
public class DAG{
// Construct an empty DAG
public DAG();
// Produce a string representaton of the DAG which shows the
// upstream and downstream links in the graph. The format should be
// as follows:
//
// Upstream Links:
// A1 : [E1, F2, C1]
// C1 : [E1, F2]
// BB8 : [D1, C1, RU37]
// RU37 : [E1]
// Downstream Links:
// E1 : [A1, C1, RU37]
// F2 : [A1, C1]
// D1 : [BB8]
// RU37 : [BB8]
// C1 : [A1, BB8]
public String toString();
// Return the upstream links associated with the given ID. If there
// are no links associated with ID, return the empty set.
//
// TARGET COMPLEXITY: O(1)
public Set<String> getUpstreamLinks(String id);
// Return the downstream links associated with the given ID. If
// there are no links associated with ID, return the empty set.
//
// TARGET COMPLEXITY: O(1)
public Set<String> getDownstreamLinks(String id);
// Class representing a cycle that is detected on adding to the
// DAG. Raised in checkForCycles(..) and add(..).
public static class CycleException extends RuntimeException{
public CycleException(String msg);
}
// Add a node to the DAG with the provided set of upstream links.
// Add the new node to the downstream links of each upstream node.
// If the upstreamIDs argument is either null or empty, remove the
// node with the given ID.
//
// After adding the new node, check whether it has created any
// cycles through use of the checkForCycles() method. If a cycle is
// created, revert the DAG back to its original form so it appears
// there is no change and raise a CycleException with a message
// showing the cycle that would have resulted from the addition.
//
// TARGET RUNTIME COMPLEXITY: O(N + L)
// MEMORY OVERHEAD: O(P)
// N : number of nodes in the DAG
// L : number of upstream links in the DAG
// P : longest path in the DAG starting from node id
public void add(String id, Set<String> upstreamIDs);
// Determine if there is a cycle in the graph represented in the
// links map. List curPath is the current path through the graph,
// the last element of which is the current location in the graph.
// This method should do a recursive depth-first traversal of the
// graph visiting each neighbor of the current element. Each
// neighbor should be checked to see if it equals the first element
// in curPath in which case there is a cycle.
//
// This method should return true if a cycle is found and curPath
// should be left to contain the cycle that is found. Return false
// if no cycles exist and leave the contents of curPath as they were
// originally.
//
// The method should be used during add(..) which will initialize
// curPath to the new node being added and use the upstream links as
// the links passed in.
public static boolean checkForCycles(Map<String, Set<String>> links, List<String> curPath);
// Remove the given id by eliminating it from the downstream links
// of other ids and eliminating its upstream links. If the ID has
// no upstream dependencies, do nothing.
//
// TARGET COMPLEXITY: O(L_i)
// L_i : number of upstream links node id has
public void remove(String id);
}
4.3 Spreadsheet
// Basic model for a spreadsheet.
public class Spreadsheet{
// Construct a new empty spreadsheet
public Spreadsheet();
// Return a string representation of the spreadsheet. This should
// show a table of the cells ids, values, and contents along with
// the upstream and downstream links between cells. Ensure that
// StringBuilder and iterators over various maps are used to
// efficiently construct the string. The expected format is as
// follows.
//
// ID | Value | Contents
// -------+--------+---------------
// A1 | 5.0 | '5'
// D1 | 4.0 | '=4'
// C1 | 178.0 | '=22*A1 + 17*D1'
// B1 | hi | 'hi'
//
// Cell Dependencies
// Upstream Links:
// C1 : [A1, D1]
// Downstream Links:
// A1 : [C1]
// D1 : [C1]
//
public String toString();
// Produce a saveable string of the spreadsheet. A reasonable format
// is each cell id and its contents on a line. You may choose
// whatever format you like so long as the spreadsheet can be
// completely recreated using the fromSaveString(s) method.
public String toSaveString();
// Load a spreadsheet from the given save string. Typical
// implementations will creat an empty spreadsheet and repeatedly
// read input from the provided string setting cells based on the
// contents read.
public static Spreadsheet fromSaveString(String s);
// Check if a cell ID is well formatted. It must match the regular
// expression
//
// ^[A-Z]+[1-9][0-9]*$
//
// to be well formatted. If the ID is not formatted correctly, throw
// a RuntimeException. The str.matches(..) method is useful for
// this method.
public static void verifyIDFormat(String id);
// Retrive a string which should be displayed for the value of the
// cell with the given ID. Return "" if the specified cell is empty.
public String getCellDisplayString(String id);
// Retrive a string which is the actual contents of the cell with
// the given ID. Return "" if the specified cell is empty.
public String getCellContents(String id);
// Delete the contents of the cell with the given ID. Update all
// downstream cells of the change. If specified cell is empty, do
// nothing.
public void deleteCell(String id);
// Set the given cell with the given contents. If contents is "" or
// null, delete the cell indicated.
public void setCell(String id, String contents);
// Notify all downstream cells of a change in the given cell.
// Recursively notify subsequent cells. Guaranteed to terminate so
// long as there are no cycles in cell dependencies.
public void notifyDownstreamOfChange(String id);
}
4.4 FNode and TokenType
These two classes are provided and do not require modification. Find them in the HW distribution code.
// Represent elements of a binary abstract syntax tree for basic
// spreadsheet formulas like '=A1 + -5.23 *(2+3+A4) / ZD11'.
//
// This class does not require modification.
public class FNode {
// Type of token at this node. May be one of the following values:
// TokenType.Plus
// TokenType.Minus
// TokenType.Multiply
// TokenType.Divide
// TokenType.Negate
// TokenType.CellID
// TokenType.Number
public TokenType type;
// Raw data for this node. May be a number, operator, or an id for
// another cell.
public String data;
// Left and right branch of the tree. One or the other may be null
// if syntax dictates a null child. Notably, for unary negation the
// left child is the subtree that is negated and the right tree is
// empty. Examine the implementation of FormulaVisitorImpl method
// for details.
public FNode left, right;
// Construct a node with the given data.
public FNode(TokenType type, String data, FNode left, FNode right);
// Constructor a node with the given data
public FNode(TokenType type, FNode left, FNode right);
// Create a fancy-ish string version of this node. Enters a
// recursive version of the method
public String toString();
// Class to cause immediate exception percolation on encountering an
// error in the input of the formula grammar.
//
// Adapted from The Definitive ANTLR 4 Reference, 2nd Edition" section 9.2
public static class FailOnErrorListener extends BaseErrorListener {
}
// Construct a tree based on the provided formula string. Primary
// means to construct trees.
public static FNode parseFormulaString(String formulaStr);
// Main method to test construction. Attempts to parse the formula
// given as the first command line argument and print out its contents as a parsed tree.
//
// Example:
// > java -cp .:formula.jar FNode '=A1 + -5.23 *(2+3+A4) / ZD11'
public static void main(String[] args) throws Exception ;
// Class which visits an ANTLR parse tree for the Formula grammar and
// builds a tree of FNodes. Basic usage is as follows such as in a
// main() method:
//
// ANTLRInputStream input = new ANTLRInputStream(formulaStr);
// FormulaLexer lexer = new FormulaLexer(input);
// CommonTokenStream tokens = new CommonTokenStream(lexer);
// FormulaParser parser = new FormulaParser(tokens);
// ParseTree tree = parser.input();
// FNode root = (new FormulaVisitorImpl()).visit(tree);
//
public static class FormulaVisitorImpl extends FormulaBaseVisitor<FNode>{
public FNode visitAll(FormulaParser.AllContext ctx) ;
public FNode visitPlus(FormulaParser.PlusContext ctx) ;
public FNode visitMinus(FormulaParser.MinusContext ctx) ;
public FNode visitMultiply(FormulaParser.MultiplyContext ctx) ;
public FNode visitDivide(FormulaParser.DivideContext ctx) ;
public FNode visitNegation(FormulaParser.NegationContext ctx) ;
public FNode visitCellID(FormulaParser.CellIDContext ctx) ;
public FNode visitNumber(FormulaParser.NumberContext ctx) ;
public FNode visitBraces(FormulaParser.BracesContext ctx) ;
}
}
// Types of tokens that can appear in a formula
public enum TokenType {
// String representation of the token
public String typeString;
}
5 Cells and Formulas
Spreadsheet cells contain data in one of three forms: strings,
numbers, or formulas. You may choose to subclass Cell for different
types of cells or implement all functionality within Cell.java. The
primary responsibility of a Cell is to provide a value when asked.
This is easy for strings and numbers whose value is simple. Formulas
on the other hand must be evaluated to produce a number and sometime
re-evaluated if the cells on which they depend change value. The
subsections below explain various aspects of implementing Cells.
5.1 Cell Creation and kind: Cell.make(contents)
While Cell may have constructors, the only required method for
Cell creation is a static factory method called make(contents).
Cells can be created with the make() method as follows.
Cell numCell = Cell.make(" 1.23 ");
Cell strCell = Cell.make("hi there ");
Cell frmCell = Cell.make(" =1.5 * A2 / (D1+B3) ");
Note that this opens the possibility that the return value of make()
might actually be a sub-class of Cell which is specialized to the
type of cell. This is a design decision which you can opt for though
it is not required. Also note that there is whitespace at the
beginning and end of the contents which should be removed with a call
to the string method trim().
A cell can be identified as string, number, or formula via its
kind() method which returns a string.
System.out.println( numCell.kind() ); // "number" System.out.println( strCell.kind() ); // "string" System.out.println( frmCell.kind() ); // "formula"
All Cells can be asked about their contents and numeric value. The
contents are simply the trimmed contents string used to create the
cell. The numeric value is null for kind "string" cells, the double
value associated with numbers, and double result of evaluating a
formula cell. To evaluate a formula it must be updated which requires
a map of ids like A1, D7, C22 to Cell objects. This is
discussed in the section on Formula Evaluation.
// note that contents are trimmed System.out.println( numCell.contents() ); // "1.23" System.out.println( strCell.contents() ); // "hi there" System.out.println( frmCell.contents() ); // "=1.5 * A2 / (D1+B3)" System.out.println( numCell.numberValue() ); // 1.23 System.out.println( strCell.numberValue() ); // null // frmCell has not yet been updated so is in the ERROR state System.out.println( frmCell.numberValue() ); // null System.out.println( frmCell.displayString() ); // "ERROR" System.out.println( frmCell.isError() ); // true // updating the value using a provided map adjust frmCell frmCell.updateValue(idToCellMap); // evaluate the formula with other cells System.out.println( frmCell.numberValue() ); // 7.90 System.out.println( frmCell.displayString() ); // "7.90" System.out.println( frmCell.isError() ); // false
5.2 Determining Cell Kind
- Number cells are identified if the contents passed to
Cell.make(contents)can be parsed with the methodDouble.parseDouble(contents). If this method does not throw an exception, treat the contents as a double. - If an exception is thrown, then the contents must represent a formula or a string.
- Formula can be identified by inspecting the 0th character of the contents. If it is the equals sign (=), the cell is a formula.
- If the cell is neither a number nor a formula, it is a string.
5.3 Formula Parsing
Cells with formulas can be identified by the 0th character in their
trimmed contents string being the equals sign (=). Parsing formulas
is a nontrivial task that is best left to a library. A class called
FNode is provided which uses the ANTLR parsing library stored in the
formula.jar file to perform parsing for you. FNode has a static
method called parseFormulaString(frmStr) which will parse valid
formulas and produce a binary tree of FNode objects representing the
abstract syntax tree of the formula. This method is invoked as
follows:
String formulaString = "=8/2+2*3 + A7*C2"; FNode treeRoot = FNode.parseFormulaString(formulaString);
The resulting FNode will be the root + node of the following
abstract syntax tree, give both as a picture and as a textual layout
of the tree.
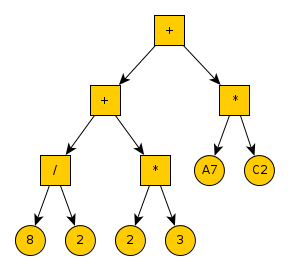
Figure 3: Abstract syntax tree of FNodes for the formula "=8/2+2*3 + A7*C2"
+
+
/
8
2
*
2
3
*
A7
C2
You can experiment with parsing with the main() method in FNode to
see how various formulas are parsed. It takes a formula on the command
line, parses it and prints a "pretty" version of the parse tree which
uses indentation to show the tree and children: sibling nodes are at
the same indentation level in the print out.
> javac -cp formula.jar:. FNode.java
> java -cp formula.jar:. FNode "=1"
1
> java -cp formula.jar:. FNode "=1+2*3"
+
1
*
2
3
> java -cp formula.jar:. FNode "=8/2+2*3"
+
/
8
2
*
2
3
> java -cp formula.jar:. FNode "=8/(B2+D2)*3+A1"
+
*
/
8
+
B2
D2
3
A1
Cells which are to hold formulas should have a field which stores the
root FNode that is produced by a call to
parseFormulaString(frmStr). In the event that the formula is
invalid (ex: parseFormulaString("= 1 / * 2")), an exception is
thrown by parseFormulaString() which should be allowed to percolate
up and out of Cell.make(contents).
5.4 Evaluating Formulas Based on Abstract Syntax Trees
Once a cell has been created with a formula in it, there should be an
FNode as the root of the abstract syntax tree representing the
formula. Abstract syntax trees are useful in that only elements that
"count" are present: whitespace has been removed and parenthesis and
operator precedence are reflected in the structure of the tree. For
example consider the two similar formulas below which result in
different abstract syntax tree structures.
> java -cp formula.jar:. FNode "=4 + 3 * 2"
+
4
*
3
2
# implicit grouping, multiplaction first =4 + (2*3)
# evaluates to 10
> java -cp formula.jar:. FNode "=(4 + 3) * 2"
*
+
4
3
2
# explicit grouping: addition first
# evaluates to 14
The ambiguities of syntax are laid bare by the tree structure.
FNodes have a field called type which has values in the
TokenType enumeration which indicate whether the node contains a
number, a cell id like E17, or whether the node is a numeric
operator like + or /.
To evaluate a formula, utilize a post-order traversal of the tree of
FNodes. Recall that during a post-order traversal, both children
are visited then the present node is dealt with. In this context,
visiting children will be to determine their numeric value while
dealing with the present node is a matter of applying whatever
operator happens to be at that node. Base cases are leaf nodes which
are always either number or the ids of some other cells involved in
the formula.
The method evalFormulaTree(..) evaluates a given formula node in the
context of some mapping of string ids like E17 to cells.
public static Double evalFormulaTree(FNode node, Map<String,Cell> cellMap)
It should use a recursive post-order traversal to accomplish this. The general approach is divided into the following cases:
FNodeswith typeTokenType.Numbershould return thedoubleassociated with parsing theirdatafieldFNodeswith typeTokenType.CellIDshould retrieve the cell from the providedcellMapusing thedatafield of theFNodeas the lookup key. The numeric value (double) from cell should be returned.- Nodes representing binary operators
+,-,*,/have types likeTokenType.Plus. Recurse on the the left and right children to find their numeric values. Then apply the appropriate operation (addition, subtraction, etc.) to the two numbers and return the result. FNodesmay have typeTokenType.Negatewhich represents unary negation in a formula like5 * (-A7) + -(2+B7)where both cellA7and the expression(2+B7)are negated. In these cases, the left child of theFNodecontains the subtree to be negated while the right child is null.
Cell.evalFormulaTree(..) is a static method which can be called
without any particular cell associated. This is partially for testing
purposes. However, its primary purpose is in the method
cell.updateValue(cellMap) which should call evalFormulaTree(..)
when asked to update the value of a formula cell.
5.5 Errors in Formulas
It is possible for a cell formula to include un-usable cell
references. If a referenced cell contains a string (not a number) or
has no contents in it at all, it is not possible to compute a numeric
value for the cell. In these cases the cell with the formula goes into
an error state and should display ERROR with its displayString()
method. One can query whether the Cell is in an error state with
boolean err = cell.isError();.
During evaluation of evalFormulaTree(..) if unusable cells are
encountered, throw an EvalFormulaException as defined below. This
class should be nested inside of Cell as it is not widely used.
public class Cell{
// A simple class to reflect problems evaluating a formula tree.
public static class EvalFormulaException extends RuntimeException{
public EvalFormulaException(String msg){
super(msg);
}
}
}
Calls to the updateValue(..) method of a cell should catch
exceptions coming out of evalFormulaTree(..) and set the state of
the cell to be in error but not propagate the exception up.
Note that formula cells are in the error state immediately after being
created as the Cell.make(frm) method does not include a map of other
cells to evaluate formulas.
Cell frmCell = Cell.make(" =1.5 * A2 / (D1+B3) ");
// frmCell has not yet been updated so is in the ERROR state
System.out.println( frmCell.numberValue() ); // null
System.out.println( frmCell.displayString() ); // "ERROR"
System.out.println( frmCell.isError() ); // true
// updating the value using a provided map adjust frmCell
frmCell.updateValue(idToCellMap); // evaluate the formula with other cells
System.out.println( frmCell.numberValue() ); // 7.90
System.out.println( frmCell.displayString() ); // "7.90"
System.out.println( frmCell.isError() ); // false
5.6 Upstream Dependencies in Formulas
Formulas can depend on the value of other cells such as in
=2*A5 + D2
if either cell A5 or D2, cells with the above formula should be
notified of the change by calling their updateValue(map) method.
Ultimately the Spreadsheet class will do this but cells must provide
the other cells on which they depend. This is done via the
getUpstreamIDs() method.
public Set<String> getUpstreamIDs()
For number and string cells, this simply returns an empty set as these have no dependencies on other cells.
Formula cells must traverse their formula tree to find all cell ids
and return these as a Set. For this, define a recursive helper
method which is invoked in getUpstreamIDs(). You will likely pass
an empty set as an argument to this helper method. Every time a cell
ID is encountered in the formula tree (TokenType.CellID), add the
ID to the set and recurse.
6 DAG: Directed Acyclic Graphs for Circular Reference Detection
Since formulas can reference one another, there is a danger that one can create a circular reference which makes the evaluation of such formulas ambiguous. Consider the introduction example earlier mentioned in the overview section:
ID | Value | Contents
-------+--------+---------------
A1 | 1.0 | '=A3+5' // depends on A3
A3 | 1.3 | '=B1 / (C2-2)' // depends on C2
C2 | 6.0 | '=A1+B1' // depends on A1 - cycle
B1 | 5.0 | '5'
- Starting from
A1, the value ofA3is required to evaluate the formula A3in turn depends onB1which is not problematic, but alsoC2C2depends onA1but this is where the evaluation started- A cycle exists in the graph of connections
[A1, A3, C2, A1]
Preventing such cycles from being introduced into the the spreadsheet
is the primary responsibility of the DAG class, but a bit of
introduction is in order first.
A graph is a general concept in which nodes are linked together (formally vertices are connected via edges but node/link are common terminology as well). You will learn about general graph properties at some point during your CS education as a variety of practical problems can be represented by graphs and solved via algorithms upon them.
Many graphs are directed in that the links between nodes are a
one-way connection. In our setting, this direction is a "depends on"
relationship: cell X depends on cell Y to calculate its value because
Y appears in the formula for X. There will thus be a link from X to
Y in the graph of dependencies. This will be referred to in the
following terms:
- Cell
Yis upstream fromXifYappears in the formula inX - Cell
Xis downstream fromYifXneeds to know the value ofY - When
Yhas its value changed, the update needs to flow downstream to cells that use its value
Most of you are acquainted with the fact that water flows downstream in most cases and does not create circles. This is important in the spreadsheet as well to prevent circular references between cells. This will be detected by maintaining a Directed Acyclic Graph which is a graph with the following special properties.
#/media/File:Escher_Waterfall.jpg){kind=link}
- It is directed in that the links are one-directional
- There are no cycles in the graph: starting from a node and following links in their given direction, one can never return to the starting node.
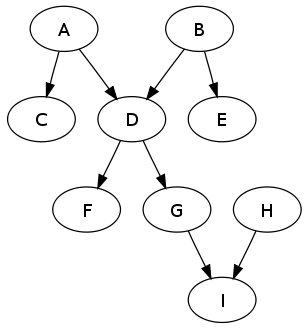
Figure 4: A simple directed acyclic graph (DAG). No cycles are possible.
The DAG.java class will be responsible for maintaining a directed
acyclic graph of dependencies between cells with formulas. Every time
a formula is installed, it and its upstream links (cells on which it
depends) will be added to the DAG. The DAG will perform an
analysis which determines whether the addition creates any cycles. If
not, the addition is committed. If a cycle would be introduced, the
add request triggers an exception which does not change the DAG. The
exception message reports a cycle that would be introduced.
6.1 DAG Internal Structure
Graphs are often represented as sets of links between nodes. In our
case we will want to retrieve upstream or downstream links based on a
cell ID like "get the cells that are downstream from A2 as its value
was just changed." This format strong suggest maintaining two maps
within DAG
- A map from
String idto theSetof downstream node IDs - A map from
String idto theSetof upstream node IDs - Both of these should be
HashMapsto meet the target lookup complexities ofO(1).// Return the upstream links associated with the given ID. If // there are no links associated with ID, return the empty set. // // TARGET COMPLEXITY: O(1) public Set<String> getUpstreamLinks(String id); // Return the downstream links associated with the given ID. If // there are no links associated with ID, return the empty set. // // TARGET COMPLEXITY: O(1) public Set<String> getDownstreamLinks(String id);
6.2 Adding and Removing Nodes
In order for a DAG to have any upstream and downstream nodes to
retrieve, it must be able to add(..) new nodes and conversely
remove(..) them. These two operations have the following
signatures.
// TARGET COMPLEXITY: O(N + L) // N : number of nodes in the DAG // L : number of links in the DAG public void add(String id, Set<String> upstreamIDs); // TARGET COMPLEXITY: O(L_i) // L_i : number of upstream links node id has public void remove(String id);
Adding a new node requires its upstream dependencies to be provided. For example:
Welcome to DrJava.
> DAG dag = new DAG();
> dag
Upstream Links:
Downstream Links:
> dag.add("A1",DAGDemo.toSet("B1","C1","D1"));
> dag
Upstream Links:
A1 : [D1, C1, B1]
Downstream Links:
D1 : [A1]
C1 : [A1]
B1 : [A1]
The utility function DAGDemo.toSet(..) is used here to create a set
of strings to add as the upstream IDs; it is not needed for
implementation of the project, only as a way to make the examples read
shorter.
Notice in the example above that on adding A1, its upstream links
appear in the upstream links map as initially presented. Notice also
that the downstream links map has been adjusted so that the nodes on
which A1 depends now include it as a link. Further additions alter
the Upstream and Downstream Links.
> dag.add("B1",DAGDemo.toSet("C1","E1"))
> dag
Upstream Links:
A1 : [D1, C1, B1]
B1 : [E1, C1]
Downstream Links:
E1 : [B1]
D1 : [A1]
C1 : [A1, B1]
B1 : [A1]
> dag.add("D1",DAGDemo.toSet("C1","B1"))
> dag
Upstream Links:
A1 : [D1, C1, B1]
D1 : [C1, B1]
B1 : [E1, C1]
Downstream Links:
E1 : [B1]
D1 : [A1]
C1 : [A1, D1, B1]
B1 : [A1, D1]
// Adding an existing node overwrites the previous version of the
// node. Notice that the upstream and downstream links change when A1
// is re-added. This can be accomplished by removing A1 first then
// re-adding it. Since no nodes depend on D1 anymore, it no longer
// appears in the downstream links.
> dag.add("A1",DAGDemo.toSet("B1","C1","E1"));
> dag
Upstream Links:
A1 : [E1, C1, B1]
D1 : [C1, B1]
B1 : [E1, C1]
Downstream Links:
E1 : [A1, B1]
C1 : [A1, D1, B1]
B1 : [A1, D1]
// Adding a node with no upstream depencies does not alter the DAG if
// the node is not already present in the DAG
> dag.add("E1",DAGDemo.toSet())
> dag
Upstream Links:
A1 : [E1, C1, B1]
D1 : [C1, B1]
B1 : [E1, C1]
Downstream Links:
E1 : [A1, B1]
C1 : [A1, D1, B1]
B1 : [A1, D1]
// Removing a node eliminates its upstream links and eliminates it
// from the downstream links of upstream nodes. It does not remove its
// downstream links.
> dag.remove("B1")
> dag
Upstream Links:
A1 : [E1, C1, B1]
D1 : [C1, B1]
Downstream Links:
E1 : [A1]
C1 : [A1, D1]
B1 : [A1, D1]
> dag.remove("A1")
> dag
Upstream Links:
D1 : [C1, B1]
Downstream Links:
C1 : [D1]
B1 : [D1]
6.3 Cycle Detection with Depth First Search
During the add(..) method, DAGs must detect whether adding a new
node would create a cycle which would violate the acyclic property.
This is typically done with a recursive depth-first search, a way of
searching the entire graph. The search is started at a designated
node, usually the new node which is added. Each of its upstream
dependencies is visited in a recursive call which in turn will visit
each of their upstream nodes in turn and so forth. During the
depth-first search, a path of the nodes that have been visited is
maintained. Each new addition is checked against the first node in the
path and if the two are equal, then a cycle exists as the path has
returned to the starting point.
A recursive helper method with the following signature should be
implemented for cycle checks. The links in this case are the
upstream links in the DAG and the curPath should be initialized to
contain the new node that is being added.
public static boolean checkForCycles(Map<String, Set<String>> links, List<String> curPath)
Pseudocode for this the method is provided below.
boolean checkForCycles(LINKS, PATH)
LASTNODE = get last element from PATH
NEIGHBORS = get set of neighbors associated with LASTNODE from LINKS
if NEIGHBORS is empty or null then
return false as this path has reached a dead end
otherwise continue
for every NID in NEIGHBORS {
append NID to the end of PATH
if the first element in PATH equals NID then
return true because PATH now contains a cycle
otherwise continue
RESULT = checkForCycles(LINKS,PATH) // recursively visit the neighbor
if RESULT is true then
return true because PATH contains a cycle
otherwise continue
remove the last element from PATH which should be NID
}
after exploring all NEIGHBORS, no cycles were found so
return false
You will need to convert the above pseudocode to proper Java to
implement checkForCycles(..).
The dag.add(..) method should not change the DAG if a cycle would
be created. It should throw a DAG.CycleException which is a simple
extension of RuntimeException. The message in the exception should
contain the cycle that was found as a list. You may copy this
definition for the class:
// Class representing a cycle that is detected on adding to the
// DAG. Raised in checkForCycles(..) and add(..).
public static class CycleException extends RuntimeException{
public CycleException(String msg){
super(msg);
}
}
Here are some examples of add(..) failing due to cycles.
> DAG dag = new DAG();
> dag
Upstream Links:
Downstream Links:
> dag.add("A1",DAGDemo.toSet("A1"));
DAG$CycleException: [A1, A1]
at DAG.add(DAG.java:97)
// Adding a cycle fails leaving the DAG unchanged
> dag
Upstream Links:
Downstream Links:
> dag.add("A1",DAGDemo.toSet("B1"));
> dag
Upstream Links:
A1 : [B1]
Downstream Links:
B1 : [A1]
> dag.add("B1",DAGDemo.toSet("A1"));
DAG$CycleException: [B1, A1, B1]
at DAG.add(DAG.java:97)
// Adding a cycle fails leaving the DAG unchanged
> dag
Upstream Links:
A1 : [B1]
Downstream Links:
B1 : [A1]
> dag.add("B1",DAGDemo.toSet("C1"));
> dag
Upstream Links:
A1 : [B1]
B1 : [C1]
Downstream Links:
C1 : [B1]
B1 : [A1]
> dag.add("C1",DAGDemo.toSet("A1"));
DAG$CycleException: [C1, A1, B1, C1]
at DAG.add(DAG.java:97)
> dag.add("C1",DAGDemo.toSet("D1","E1","F1"));
> dag
Upstream Links:
A1 : [B1]
C1 : [F1, E1, D1]
B1 : [C1]
Downstream Links:
F1 : [C1]
E1 : [C1]
D1 : [C1]
C1 : [B1]
B1 : [A1]
> dag.add("F1",DAGDemo.toSet("E1"));
> dag
Upstream Links:
A1 : [B1]
F1 : [E1]
C1 : [F1, E1, D1]
B1 : [C1]
Downstream Links:
F1 : [C1]
E1 : [F1, C1]
D1 : [C1]
C1 : [B1]
B1 : [A1]
> dag.add("F1",DAGDemo.toSet("B1"));
DAG$CycleException: [F1, B1, C1, F1]
at DAG.add(DAG.java:97)
> dag.add("F1",DAGDemo.toSet("A1"));
DAG$CycleException: [F1, A1, B1, C1, F1]
at DAG.add(DAG.java:97)
> dag
Upstream Links:
A1 : [B1]
F1 : [E1]
C1 : [F1, E1, D1]
B1 : [C1]
Downstream Links:
F1 : [C1]
E1 : [F1, C1]
D1 : [C1]
C1 : [B1]
B1 : [A1]
6.4 String Display of DAGs
When displaying DAGs, show both their upstream and downstream
links. Leave 4 characters for each ID in the link sections and follow
it with the toString() version of whatever Set you have selected
to use.
Upstream Links:
A1 : [E1, F2, C1]
C1 : [E1, F2]
BB8 : [D1, C1, RU37]
RU37 : [E1]
Downstream Links:
E1 : [A1, C1, RU37]
F2 : [A1, C1]
D1 : [BB8]
RU37 : [BB8]
C1 : [A1, BB8]
^^^^
1234 - 4 characters wide, padded with whitespace
String.format("%4s",str) is very useful for this.
6.5 Memory Efficient DAG.add(id,upstream) Implementation
A common first pass at implementing add(id,upstream) is to simply
make a copy of the entire DAG (upstream/downstream maps) before
altering it and if a cycle results, restore the DAG with the saved
map copies. This is easy to do but is memory inefficient: making a
copy of a 10,000 node DAG just to add one node is overkill. This is
also a violation of the memory O(P) memory constraint of add(..)
which is meant to indicate that only the stack space for cycle
checking should be large.
Instead take the following actions which make copies of only of the
old IDs associated with the id being changed.
During a call to add(id, newUpstreamIDs):
- Retrieve the current upstream links associated with
idand save them in a local variable - Remove
idfrom the DAG which should clear its upstream links and remove it from the downstream links of the other nodes. A call toremove(id)is useful to make this portion short. - Change the upstream links associated with
idto thenewUpstreamLinks. - For each of the nodes in
newUpstreamLinks, addidto its downstream links. - At this point the
idshould now be installed in the DAG but may have introduced a cycle - Check for the presence of a cycle with the current upstream links
starting at
id. - If no cycle results,
add(..)is successful and can return. - If a cycle resulted, store the cycle in a local variable.
- Restore the old upstream links associated with
idby using the local variable which saved the old links earlier; a call toadd(..)which is somewhat recursive can make this process easy. Note that the recursion should only go one layer deep though: theidpreviously did not have a cycle associated with it so the restoringadd(..)call should complete. - The DAG should now be restored to its original state prior to the
current
add(..)and aCycleExceptionshould be thrown with the cycle that was discovered
7 Spreadsheet: Tying it all Together
The Spreadsheet class stitches together the other classes to create
a working spreadsheet model. This is not an application, merely an
object that a user interface like AckCell.java can use as the back
end for an application.
7.1 Cell Maps and Valid Cell IDs
The central features of the Spreadsheet are that it tracks a mapping
from valid string IDs to Cell objects (likely via a
HashMap<String,Cell>) and that it will maintain a DAG of
dependencies between cells which can be used to notify cells of
changes that might affect it.
On installing cells, the spreadsheet should verify that the ID
associated with the cell is valid, formatted like AB12, X19, or
BB8 rather than hello 123 or Zoinks!. This should be done via
the verifyIDFormat(id) method and should make use of the the string
matches(regex) method using the provided regular expression.
// Check if a cell ID is well formatted. It must match the regular expression // ^[A-Z]+[1-9][0-9]*$ // to be well formatted public static void verifyIDFormat(String id)
Note that regular expressions are an incredibly useful tool that every self-respecting CSer should seek to master as they make life much easier.
7.2 Setting Contents of Cells
The main work of Spreadsheet is in the setCell(id,contents) method
which will need to create a cell, add it to the map, update the DAG,
and notify all cells which might depend on the new cell.
// Set the given cell with the given contents. If contents is "" or // null, delete the cell indicated. public void setCell(String id, String contents)
Spreadsheets maintain a map from IDs to Cells and an internal DAG
to track dependencies between cells. The basic process of setting a
cell in the spreadsheet with a call like
sheet.setCell("B6","=A21*2 + C2");
is as follows.
- Delete any contents associated with
B6in the map from ids toCells - Create a new cell with the contents
A21*2 + C2 - Extract the upstream dependencies for the cell which are
A21andC2 - Attempt to add
B6to the spreadsheet'sDAGwith its upstream dependencies - If successful, no cycles are created and the new
Cellis valid - Associate in the spreadsheet's map
B6with the newly createdCell - Update the value of that cell passing in the spreadsheet's ID /
Cellmap so thatB6can look up the number values ofA21andC2 - Notify any cells that are downstream from
B6that its contents have changed
In particular, the update method notifyDownstreaOfChange(id) should
be employed. It should visit each downstream cell form the given ID
and invoke its cell.updateValue(..) method, then recursively notify
all downstream cells from them.
// Notify all downstream cells of a change in the given cell. // Recursively notify subsequent cells. Guaranteed to terminate so // long as there are no cycles in cell dependencies. public void notifyDownstreamOfChange(String id);
Cells can be deleted via the deleteCell(id) method.
// Delete the contents of the cell with the given ID. Update all // downstream cells of the change. public void deleteCell(String id)
This should remove the cell from the internal map and DAG and notify
any downstream cells that depended on it that the cell is now blank
which is likely to cause some cells to go into an ERROR state.
7.3 Saving and Loading Spreadsheets
Finally, Spreadsheets provide save and load facilities via their
toSaveString() method and the static factory method
fromSaveString(saveString) method. You are free to choose your own
format for saving and loading. Keep in mind that the format of
spreadsheet.toString() is rather complex and not easy to read back
in using a java.util.Scanner so you should consider a simpler
format. All that really matters for recreating a spreadsheet are the
Cell contents so a good format might be along the lines of the example
given below in which each line contains the cell ID and the remainder
of the line contains the contents of the cell. This makes it easy to
use the next() and nextLine() methods of Scanner to parse the
input string.
Welcome to DrJava.
> Spreadsheet sheet = new Spreadsheet();
> sheet.setCell("C1"," =A1 * (5+A1) ")
> sheet.setCell("A1","5")
> sheet.setCell("B1","hi")
> sheet.setCell("D1","= -C1 + 2.5*A1 -3")
> sheet
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
D1 | -40.5 | '= -C1 + 2.5*A1 -3'
C1 | 50.0 | '=A1 * (5+A1)'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
C1 : [A1]
Downstream Links:
A1 : [D1, C1]
C1 : [D1]
// Simple example of save string; format is not required; select a
// format which you find easy to parse with fromSaveString(str)
> sheet.toSaveString()
"A1 5
D1 = -C1 + 2.5*A1 -3
C1 =A1 * (5+A1)
B1 hi
"
// toSaveString() should be readable by fromSaveString(str) and can be
// used to create copies of the sheet
> Spreadsheet copy = Spreadsheet.fromSaveString(shet.toSaveString());
> copy
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
D1 | -40.5 | '= -C1 + 2.5*A1 -3'
C1 | 50.0 | '=A1 * (5+A1)'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
C1 : [A1]
Downstream Links:
A1 : [D1, C1]
C1 : [D1]
7.4 Demonstration of Spreadsheet Functionality
Below are examples of many of the methods associated with the
SpreadSheet class and the expected behavior
Welcome to DrJava.
> Spreadsheet sheet = new Spreadsheet();
> sheet.setCell("C1"," =A1 * (5+A1) ")
> sheet.setCell("A1","5")
> sheet.setCell("B1","hi")
> sheet
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
C1 | 50.0 | '=A1 * (5+A1)'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
C1 : [A1]
Downstream Links:
A1 : [C1]
> sheet.setCell("D1","= -C1 + 2.5*A1 -3")
> sheet
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
D1 | -40.5 | '= -C1 + 2.5*A1 -3'
C1 | 50.0 | '=A1 * (5+A1)'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
C1 : [A1]
Downstream Links:
A1 : [D1, C1]
C1 : [D1]
// Simple example of save string; format is not required
> sheet.toSaveString()
"A1 5
D1 = -C1 + 2.5*A1 -3
C1 =A1 * (5+A1)
B1 hi
"
// Example of deletion; note that D1 becomes an error as its upstream
// dependency C1 is now empty.
> sheet.deleteCell("C1")
> sheet
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
D1 | ERROR | '= -C1 + 2.5*A1 -3'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
Downstream Links:
A1 : [D1]
C1 : [D1]
> sheet.setCell("C1","=2.5")
> sheet
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
D1 | 7.0 | '= -C1 + 2.5*A1 -3'
C1 | 2.5 | '=2.5'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
Downstream Links:
A1 : [D1]
C1 : [D1]
> sheet.getCellDisplayString("C1")
"2.5"
> sheet.getCellContents("C1")
"=2.5"
> sheet.getCellDisplayString("D1")
"7.0"
> sheet.getCellContents("D1")
"= -C1 + 2.5*A1 -3"
// Cycles in cell references are detected
> sheet.setCell("A1","=2*D1")
DAG$CycleException: Cell A1 with formula '=2*D1' creates cycle: [A1, D1, A1]
at Spreadsheet.setCell(Spreadsheet.java:144)
// No change after the a failed cycle add
> sheet
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
D1 | 7.0 | '= -C1 + 2.5*A1 -3'
C1 | 2.5 | '=2.5'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
Downstream Links:
A1 : [D1]
C1 : [D1]
// Identify bad ids for cells: must match the regular expression
// mentioned with verifyIDFormat(id)
> sheet.setCell("zebra","1")
java.lang.RuntimeException: Cell id 'zebra' is badly formatted
at Spreadsheet.verifyIDFormat(Spreadsheet.java:89)
at Spreadsheet.setCell(Spreadsheet.java:132)
> sheet.setCell("a7","1")
java.lang.RuntimeException: Cell id 'a7' is badly formatted
at Spreadsheet.verifyIDFormat(Spreadsheet.java:89)
at Spreadsheet.setCell(Spreadsheet.java:132)
> sheet.setCell("75","1")
java.lang.RuntimeException: Cell id '75' is badly formatted
at Spreadsheet.verifyIDFormat(Spreadsheet.java:89)
at Spreadsheet.setCell(Spreadsheet.java:132)
> sheet.setCell("ABC","1")
java.lang.RuntimeException: Cell id 'ABC' is badly formatted
at Spreadsheet.verifyIDFormat(Spreadsheet.java:89)
at Spreadsheet.setCell(Spreadsheet.java:132)
> sheet.setCell("ABC123","1")
> sheet
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
ABC123 | 1.0 | '1'
D1 | 7.0 | '= -C1 + 2.5*A1 -3'
C1 | 2.5 | '=2.5'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
Downstream Links:
A1 : [D1]
C1 : [D1]
// Simple example of save string; format is not required
> String saveString = sheet.toSaveString();
> saveString
"A1 5
ABC123 1
D1 = -C1 + 2.5*A1 -3
C1 =2.5
B1 hi
"
// Spreadsheets can be loaded from a saveString to create copies
> Spreadsheet copy = Spreadsheet.fromSaveString(saveString);
> copy
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
ABC123 | 1.0 | '1'
D1 | 7.0 | '= -C1 + 2.5*A1 -3'
C1 | 2.5 | '=2.5'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
Downstream Links:
A1 : [D1]
C1 : [D1]
// Copy is distinct from the original
> copy.setCell("A1","blerg")
> copy
ID | Value | Contents
-------+--------+---------------
A1 | blerg | 'blerg'
ABC123 | 1.0 | '1'
D1 | ERROR | '= -C1 + 2.5*A1 -3'
C1 | 2.5 | '=2.5'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
Downstream Links:
A1 : [D1]
C1 : [D1]
> sheet
ID | Value | Contents
-------+--------+---------------
A1 | 5.0 | '5'
ABC123 | 1.0 | '1'
D1 | 7.0 | '= -C1 + 2.5*A1 -3'
C1 | 2.5 | '=2.5'
B1 | hi | 'hi'
Cell Dependencies
Upstream Links:
D1 : [A1, C1]
Downstream Links:
A1 : [D1]
C1 : [D1]
8 Grading
Grading for this HW will be divided into three distinct parts:
- Part of your grade will be based on passing some automated test cases by an early "milestone" deadline. See the top of the HW specification for
- Part of your grade will be based on passing all automated test cases by the final deadline
- Part of your grad will be based on a manual inspection of your code and analysis documents by the teaching staff to determine quality and efficiency.
8.1 Milestone Automated Tests (5%)
- Prior to the final HW deadline, some credit will be garnered by submitting portions of the HW and passing some automated test cases associated with that portion
- The file
HW1MilestoneTests.javacontains tests which will be used for the HW milestone. These tests are duplicates of tests in some other testing files. - This early deadline is to encourage you to begin your work early on the project and make consistent incremental steps towards its completion.
- For details of automated tests, see the next section
- No manual inspection is done at the HW milestone, only automated tests.
- Milestone tests will not be used for the final grading.
- No late submissions are accepted for milestones and the submission link be unavailable shortly after the Milestone deadline.
8.2 Final Automated Tests (45%)
- JUnit test cases will be provided to detect errors in your code. These will be run by a grader on submitted HW after the final deadline.
- Tests may not be available on initial release of the HW but will be posted at a later time.
- Tests may be expanded as the HW deadline approaches.
- It is your responsibility to get and use the freshest set of tests available.
- Tests will be provided in source form so that you will know what tests are doing and where you are failing.
- It is up to you to run the tests to determine whether you are passing or not. If your code fails to compile against the tests, little credit will be garnered for this section
- Most of the credit will be divide evenly among the tests; e.g. 50% / 25 tests = 2% per test. However, the teaching staff reserves the right to adjust the weight of test cases after the fact if deemed necessary.
- Test cases are typically run from the command line using the
following invocation which you should verify works as expected on
your own code.
UNIX Command line instructions Compile > javac -cp .:junit-cs310.jar *.java Run tests > java -cp .:junit-cs310.jar SomeTests WINDOWS Command line instructions: replace colon with semicolon Compile > javac -cp .;junit-cs310.jar *.java Run tests > java -cp .;junit-cs310.jar SomeTests
8.3 Final Manual Inspection (50%)
- Graders will manually inspect your code and analysis documents looking for a specific set of features after the final deadline.
- Most of the time the requirements for credit will be posted along with the assignment though these may be revised as the the HW deadline approaches.
- Credit will be awarded for good coding style which includes
- Good indentation and curly brace placement
- Comments describing private internal fields
- Comments describing a complex section of code and invariants which must be maintained for classes
- Use of internal private methods to decompose the problem beyond what is required in the spec
- Some credit will be awarded for clearly adhering to the target
complexity bounds specified in certain methods. If the specification
lists the target complexity of a method as O(N) but your
implementation is actually O(N log N), credit will be deducted. If
the implementation complexity is too difficult to determine due to
poor coding style, credit will likely be deducted.
All TARGET COMPLEXITIES are worst-case run-times.
- Some credit will be awarded for turning in any analysis documents that are required by the HW specification. These typically involve analyzing how fast a method should run or how much memory a method requires and are reported in a text document submitted with your code.
9 Final Manual Inspection Criteria
9.1 Cell Design and Documentation (10%)
- There is clear documentation of how various functions of
Cellare accomplished. - The purpose of any fields of the class are described with documentation strings.
- The
isError()method is documented to indicate how error status is tracked for cells of various kinds. - If there are
Cellsubclasses, they are described and inheritance is used effectively while use ofinstanceofis avoided. - If no subclasses are present, it is clear how the single class can represent multiple kinds of information. Clarity is enhanced by documentation in comments.
- The
updateValue(cellMap)method is clearly laid out as to how each of the different types of cells get updated.
9.2 Cell Recursive Function Elegance (10%)
- The
evalFormulaTree(node,cellMap)method effectively exploits recursion to evaluate an expression tree ofFNodeswith little effort in code evalFormulaTree(node,cellMap)is used inCellto evaluate formulas for cells containing formulas- A recursive helper method is employed to aid the method
getUpstrreamIDs()in traversing an expression tree to find all cell ids
9.3 DAG Method Complexity and Elegance (10%)
It is clear that the add()/remove() and accessor methods of DAG adhere to the
specified target complexities.
// TARGET COMPLEXITY: O(1) public Set<String> getUpstreamLinks(String id) // TARGET COMPLEXITY: O(1) public Set<String> getDownstreamLinks(String id) // TARGET COMPLEXITY: O(L_i) // L_i : number of upstream links node id has public void remove(String id) // TARGET RUNTIME COMPLEXITY: O(N + L) // MEMORY OVERHEAD: O(P) // N : number of nodes in the DAG // L : number of upstream links in the DAG // P : longest path in the DAG starting from node id public void add(String id, Set<String> upstreamIDs)
The add(id,links) method should employ checkForCycles(id,map) to
do a recursive depth first traversal of the graph.
Note: To adhere to the memory complexity, copies of the
upstream/downstream maps in the DAG cannot be made. While easy, this
is not memory ultimately memory efficient. Consult the section on
Efficient add implementation in DAG for hints on how to do this.
9.4 Spreadsheet Save/Load Functionality (5%)
- A simple format for producing save strings is employed that enables easy loading
toSaveString()employs an efficient string construction class such asStringBuilder.fromSaveString()employs a straight-forward parsing mechanism such as aScanner
9.5 Spreadsheet Cell ID Verification (5%)
- The
verifyIDFormat(id)method uses the provided regular expression to check cells are named according to the standard letter/number convention verifyIDFormat(id)is used during cell addition to ensure only cells named appropriately are added to the spreadsheet
9.6 Spreadsheet setCell() and deleteCell() Notifications (5%)
- The methods to set and delete cells (
setCell(id,contents)anddeleteCell(id)) employ thenotifyDownstreamOfChange(id)method to alert downstream cells that their contents may need to be updated. - The
notifyDownstreamOfChange(id)method employs recursion to traverse all downstream dependencies from the initial cell so that changes propagate through the entire spreadsheet.
9.7 Code Readability (5%)
- Good indentation and curly brace placement is used.
- Comments are present describing private internal class fields.
- Comments describing a complex section of code and invariants which must be maintained for classes
- Informative variable names are used especially for fields of classes and important local variables. Avoid single letter variable names for class fields.
10 Setup and Submission
10.1 HW Distribution
Most programming assignments will have some code that is provided and should be used to complete the assignment.
Download it and extract all its contents; by default it will create a
directory (folder) named distrib-hwX where X is the HW number.
10.2 HW Directory
Rename the distrib-hwX directory to masonid-hwX where masonid
is your mason ID. My mason ID is ckauffm2 so I would rename HW1 to
ckauffm2-hw3.
This is your HW directory. Everything concerning your assignment will go in this directory.
10.3 ID.txt
Create a text file in your HW directory called ID.txt which has
identifying information in it. My ID.txt looks like.
Chris Kauffman ckauffm2 G001234567
It contains my full name, my mason ID, and G# in it. The presence of
a correct ID.txt helps immensely when grading lots of assignments.
10.4 Penalties
Make sure to
- Set up your HW directory correctly
- Include an
ID.txt - Indent your code and make comments
Failure to do so may be penalized by a 5% deduction.
10.5 Submission: Blackboard
Do not e-mail the professor or TAs your code.
Create a ZIP file of your HW directory and submit it to the course blackboard page. Do not submit multiple files manually through blackboard as this makes it hard to unpack large numbers of assignments. Learn how to create a zip and submit only that file.
On Blackboard
- Click on the Assignments section
- Click on the HW1 link
- Scroll down to "Attach a File"
- Click "Browse My Computer"
- Select you Zip file
You can resubmit to blackboard as many times as you like up to the deadline.