
CharDict and CharDict+
CharDict and CharDict+ are dictionaries of definitions, pronounciations, variants, and frequency for four thousand basic Chinese characters. It's important to note that in Chinese, characters are not always words. CharDict only contains characters; but CharDict+ also contains 2600 or 14,000 common compound Chinese words and definitions, depending on the dictionary option. I chiefly wrote CharDict to make it easy for me to look up single characters which I had forgotten. CharDict and CharDict+ have only been tested on the Newton MessagePad 2000.
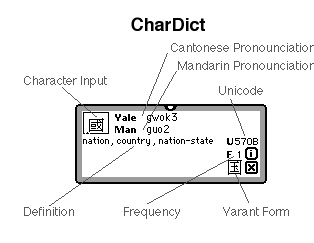
CharDict is very easy to use. Just type a character in the input field at top left. This can be done through any number of chinese input systems. You can also drag and drop chinese text into the field; but make sure you drag it into the far left (beginning) of the field; CharDict ignores all but the leftmost character in the field. If CharDict has information on this character, it displays it.
Definition. This is a short definition of the character.
Pronounciation in Cantonese. This is the Cantonese pronounciation of the character in Yale Romanization; the numbers following the text are accents as follows: 1. High and high falling. 2. High rising. 3. Middle. 4. Low Falling. 5. Low Rising. 6. Low. More information on how Yale works.
Pronounciation in Mandarin. This is the Mandarin pronounciation of the character in Pinyin romanization.
Unicode. This is the unicode value of the character (a 16-byte value in hexadecimal). Even if the character is not in the dictionary, this value will still be displayed.
Frequency. This is the frequency of the character. The values are: 1: 100 most common characters. 2: Top 500. 3. Top 1000. 4. Top 2000. 5. Top 4000.
Character Variant. This is the traditional or simplified variant of the character, if any. You can click on this character to swap the variants back and forth, making it easy to look up, then paste the simplified or traditional version of a given character.
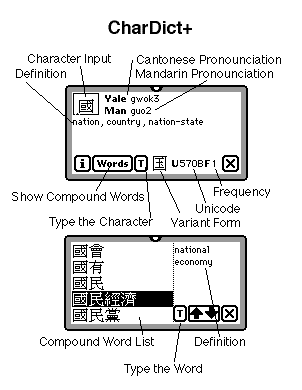
CharDict+ comes in two forms: a "small" version (677K stored in the Newton) which (plus the 4000 characters) contains 2600 compound words, and a "big" version (1676K stored in the Newton) which bumps the compound words up to a whopping 14,000. CharDict+ works just like CharDict except for:
Showing Compound Words. Press the "Words" button. A scrollable list of compound words (if any) for the given character appears (be patient--it takes a while). Select a compound word and its definition appears to the right. Note: The small version of CharDict+ takes about five seconds to load all the words for a character. The large version of CharDict+ takes twenty seconds to load all the words for a character (on an MP2000 at any rate).
Is the definition longer than the little space provided? Once you've hilighted a compound word, if you tap it again, the full definition will pop up in a notification window for you.
Press the "T" button, and the character or compound word will be typed out at your current caret position.
CharDict+ can be hidden.
The database source for CharDict is the complete Unicode database. The font CharDict uses (UniTaipeiX), while being the best chinese font available for the Newton, only can display the characters found in the GB and BIG5 encodings. A number of Unicode chinese characters, particularly some new or uncommon simplified chinese character variants, are not displayable in UniTaipieX. However, that character may still have data in CharDict, particularly if it's an (uncommon) simplified variant of a (common) traditional character -- CharDict is smart enough to look up the traditional character's definition/pronounciation/etc. for simplfied variants.
The Newton has a number of bugs which make programmming Chinese difficult. In particular, the Newton's string-comparison, string-manipulation, and database index functions do not work properly with Chinese characters. Ordinarily, CharDict+ would index all the words connected with a particular character, so lookup would be fast. But it can't, due to these bugs. So instead CharDict+ must manually sift through every single word in its database looking for terms containing the character you asked for. This can take up to 20 seconds on an MP2000 with the "huge" version of CharDict+.
The Newton's bugs (see previous question) prevent me from using the standard list display mechanism, protoSoupOverview. Instead, I have to use a substandard mechanism, protoOverview which has a number of ugly bugs that must be worked around. The workarounds cause the flashing, sorry.
The character database came from the UniHan database at Unicode.org. I don't remember where I got the small compound word database. The large compound word database is a CEDICT trimmed down by removing all 1-character words, all words greater than 6 characters, and all words which contain characters not appearing in my character database.
Important Note: The compound database used in the "big" version of CharDict+ is derived from the CEDICT and may only be used under the following lenient freeware license. Please read it.
Download CharDict as CharDict.pkg or CharDict.sit (469K stored in Newton)
Download the small version of CharDict+ as CharDictPlus.1.2.pkg or CharDictPlus.1.2.sit (677K stored in Newton)
Download the big version of CharDict+ as CharDictPlusBig.1.2.pkg or CharDictPlusBig.1.2.sit (1676K stored in Newton)
Important Note. CharDict and CharDict+ require UniTaipeiX, a chinese font available for the Newton (in the Newton it appears with the name "Taipei"). There are two versions of UniTaipeiX available. The standard version (see next section below) is designed for native speakers and uses a special hack to replace the system font so Newton menus and buttons can be customized into Chinese. Unfortunately, it also breaks some apps, most significantly, Newton Works. For non-native speakers, a better option is to use my version of UniTaipeiX which appears as an ordinary Newton font and doesn't attempt to replace any other fonts. Sean's Special UniTaipeiX.pkg or UniTaipeiX.sit (602K stored in Newton).
Free Source Code. Software developers can now download the source code to CharDict, or download the source code to CharDict+, including the small (2600) compound word dictionary. Feel free to also download the big (14,000) compound word dictionary, though adhere to the license above.
Some links to get you started: