This is a supporting page of the paper
RPM: Representative Pattern Mining for Efficient Time Series Classification
1. Abstract. Time series classification is an important problem that has received a great amount of attention by researchers and practitioners in the past two decades. In this work, we propose a novel algorithm for time series classification based on the discovery of class-specific representative patterns. We define representative patterns of a class as a set of subsequences that has the greatest discriminative power to distinguish one class of time series from another. Our approach rests upon two techniques with linear complexity: symbolic discretization of time series, which generalizes the structural patterns, and grammatical inference, which automatically finds recurrent correlated patterns of variable length, producing an initial pool of common patterns shared by many instances in a class. From this pool of candidate patterns, our algorithm selects the most representative patterns that capture the class specificities, and that can be used to effectively discriminate between time series classes. Through an exhaustive experimental evaluation we show that our algorithm is competitive in accuracy and speed with the state-of-the-art classification techniques on the UCR time series repository, robust on shifted data, and demonstrates excellent performance on real-world noisy medical time series..
2. Interpretable classification:
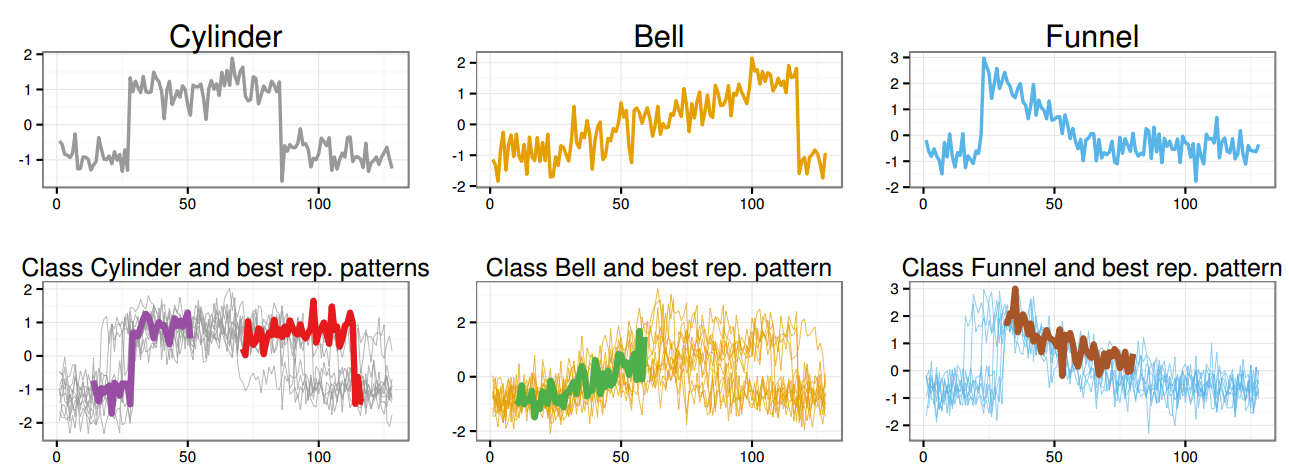
Identification of a small set of distinctive and interpretable patterns of each class allows us to exploit their key characteristics for discriminating against other classes. Here is an example for the CBF data:
3. The classification accuracy table:
Please refer to our paper for the classification accuracy on each dataset. We'll update the accuracy table on this website if there are updates for our algorithm.
4. Datasets:
Shifted Time Series Medical Alarm Data
5. Source Code:
Please contact me for the source code.