
Verti-Wheelers (VWs)

[VWs]
|
Most conventional wheeled robots can only move in flat environments and simply divide their planar workspaces into free spaces and obstacles. Deeming obstacles as non-traversable significantly limits wheeled robots' mobility in real-world, non-flat, off-road environments, where part of the terrain (e.g., steep slopes, rugged boulders) will be treated as non-traversable obstacles. To improve wheeled mobility in those non-flat environments with vertically challenging terrain, our Verti-Wheelers project introduces two wheeled platforms with little hardware modification compared to conventional wheeled robots; we collect datasets of our wheeled robots crawling over previously non-traversable, vertically challenging terrain to facilitate data-driven mobility; we also present algorithms and their experimental results to show that conventional wheeled robots have previously unrealized potential of moving through vertically challenging terrain. We make our platforms, datasets, and algorithms publicly available to facilitate future research on wheeled mobility.
|
Adaptive Planner Parameter Learning (APPL)
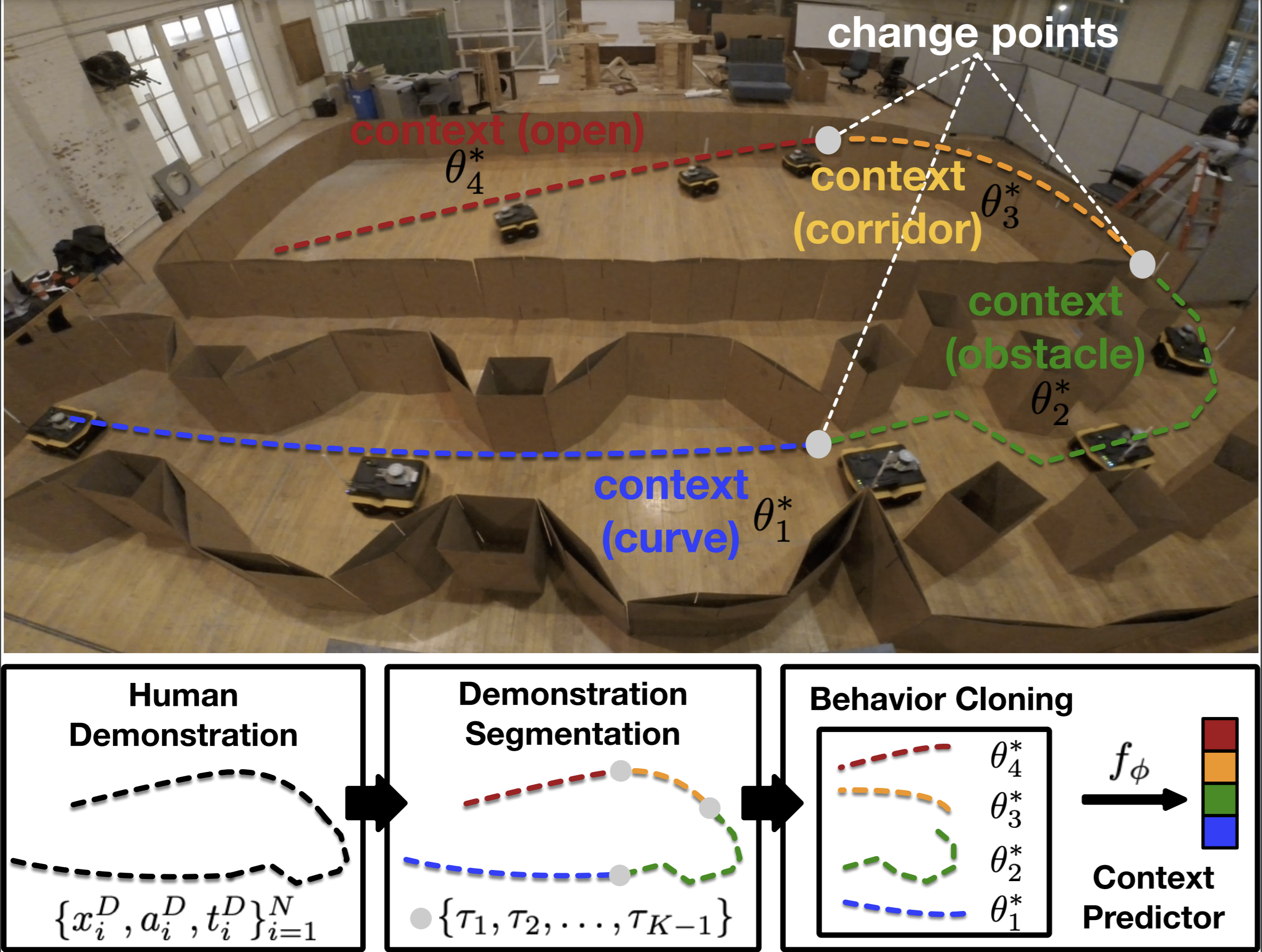
[APPL]
|
While current autonomous navigation systems allow robots to successfully drive themselves from one point to another in specific environments, they typically require extensive manual parameter re-tuning by human robotics experts in order to function in new environments. Furthermore, even for just one complex environment, a single set of fine-tuned parameters may not work well in different regions of that environment. These problems prohibit reliable mobile robot deployment by non-expert users. Adaptive Planner Parameter Learning (APPL) is a paradigm that devises a machine learning component on top of existing navigation systems to dynamically fine-tune planner parameters during deployment to adapt to different scenarios and to achieve robust and efficient navigation performance. APPL learns from different interactions modalities from non-expert users, such as teleoperated demonstration, corrective interventions, evaluative feedback, or reinforcement learning in simulation. APPL is agnostic to the underlying navigation system and inherits benefits of classical navigation systems, such as safety and explainability, while giving classical methods the flexibility and adaptivity of learning. Our experiment results show that using APPL mobile robots can improve their navigation performance in a variety of deployment environments through continual, iterative human interaction and simulation training.
|
Learning from Hallucination (LfH)
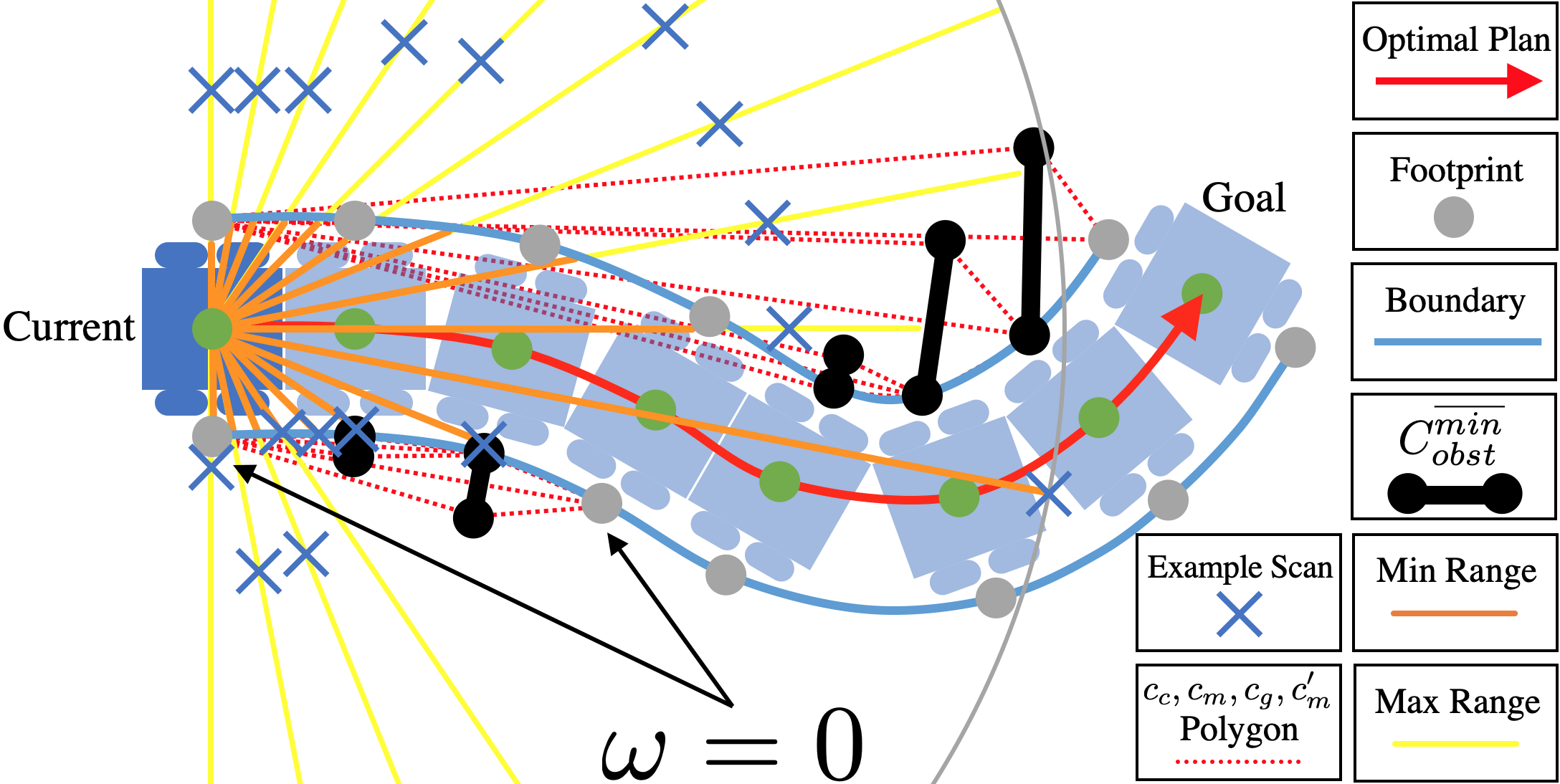
[LfH]
|
While classical approaches to autonomous robot navigation currently enable operation in certain environments, they break down in tightly constrained spaces, e.g., where the robot needs to engage in agile maneuvers to squeeze between obstacles. Classical motion planners require increased computation in those highly constrained spaces, e.g., sampling-based planners need more samples and optimization-based planners need more optimization iterations. While recent machine learning techniques have the potential to address this shortcoming, one conundrum of learning safe motion planners is that in order to produce safe motions in obstacle occupied spaces, robots need to first learn in those dangerous spaces without the ability of planning safe motions. Therefore, they either require a good expert demonstration or exploration based on trial and error, both of which become costly in highly constrained and therefore dangerous spaces. In Learning from Hallucination (LfH), we address this problem by allowing the robot to safely explore in a completely open environment without any obstacles, and then creating the obstacle configurations onto the robot perception, where the motions executed in the open training environment are optimal. In particular, we propose three hallucination methods: (1) hallucinating the most constrained obstacle set (LfH), (2) hallucinating the minimal obstacle set and then sample in addition to it (HLSD), and (3) learning a hallucination function in a self-supervised manner (LfLH). These hallucination methods can generate a large amount of training data from random exploration in open spaces without the need of expert demonstration or trial and error, from which agile motion planners can be efficiently learned to address realistic highly constrained spaces. Learning from Hallucination also allows mobile robots to improve navigation performance with increased real-world experiences in a self-supervised manner. Our experiment results show that motion planners learned from hallucination can enable agile navigation in highly constrained environments.
|
Off-Road Autonomy and Agility

|
The Off-Road Autonomy and Agility project utilizes learning-based approaches to consider the effect of unobservable world states in kinodynamic motion planning in order to enable accurate high-speed off-road navigation on unstructured terrain. Existing kinodynamic motion planners either operate in structured and homogeneous environments and thus do not need to explicitly account for terrain-vehicle interaction, or assume a set of discrete terrain classes. However, when operating on unstructured terrain, especially at high speeds, even small variations in the environment will be magnified and cause inaccurate plan execution. In this project, to capture the complex kinodynamic model and mathematically unknown world state, we learn kinodynamic planners in a data-driven manner with a variety of onboard observations, such as inertia and vision.
|
Social Robot Navigation
|
Social navigation is the capability of an autonomous agent, such as a robot, to navigate in a "socially compliant" manner in the presence of other intelligent agents such as humans. With the emergence of autonomously navigating mobile robots in human-populated environments (e.g., domestic service robots in homes and restaurants and food delivery robots on public sidewalks), incorporating socially compliant navigation behaviors on these robots becomes critical to ensuring safe and comfortable human-robot coexistence. To address this challenge, imitation learning is a promising framework, since it is easier for humans to demonstrate the task of social navigation rather than to formulate reward functions that accurately capture the complex multi-objective setting of social navigation. The use of imitation learning to social navigation for mobile robots, however, is currently hindered by a lack of large-scale datasets that capture socially compliant navigation demonstrations in the wild. To fill this gap, we introduce two imitation learning datasets for social navigation: Socially CompliAnt Navigation Dataset (SCAND) is a large-scale (8.7 hours, 138 trajectories, 25 miles), first-person view, socially compliant, human-teleoperated driving demonstrations that comprise multi-modal data streams collected on two morphologically different mobile robots by four different human demonstrators in both indoor and outdoor environments; The Multi-Modal Social Human Navigation Dataset (MuSoHu) is another large-scale (~50km, 10 hours, 150 trials, 7 humans) dataset collected by an open-source egocentric data collection sensor suite wearable by walking humans to provide multi-modal robot perception data during social human navigation in a variety of public spaces.
|

Benchmarking Autonomous Robot Navigation (BARN)

|
Designing autonomous robot navigation systems has been a topic of interest to the robotics community for decades. Indeed, many open-source implementations that allow robots to move from one point to another in a collision-free manner may create the perception that autonomous ground navigation is a solved problem. However, autonomous mobile robots still struggle in many ostensibly simple scenarios, especially during real-world deployment. For example, even when the problem is simply formulated as traditional metric navigation so that the only requirement is to avoid obstacles on the way to the goal, robots still often get stuck or collide with obstacles when trying to navigate in naturally cluttered daily households, in constrained outdoor structures including narrow walkways and ramps, and in congested social spaces like classrooms, offices, and cafeterias. In such scenarios, extensive engineering effort is typically required in order to deploy existing approaches, and this requirement presents a challenge for large-scale, unsupervised, real-world robot deployment. Overcoming this challenge requires systems that can both successfully and efficiently navigate a wide variety of environments with confidence. To raise the robotics community's awareness of such unsolved problem, the BARN dataset and its extension DynaBARN are developed as a standardized benchmark for the research community to objectively assess navigation performance in a variety of static and dynamic obstacle environments; We organize The BARN Challenge as a competition to test out state-of-the-art navigation systems, the results of which further coroborate our observation that even experienced roboticists tend to underestimate how difficult navigation scenarios are for real robots and those (ostensibly) simple metric navigation problems are still far from being solved; We also benchmark state-of-the-art reinforcement learning techniques according to four major desiderata when deploying reinforcement learning methods in real-world autonomous navigation.
|
Risk-Awareness in Unstructured or Confined Environments
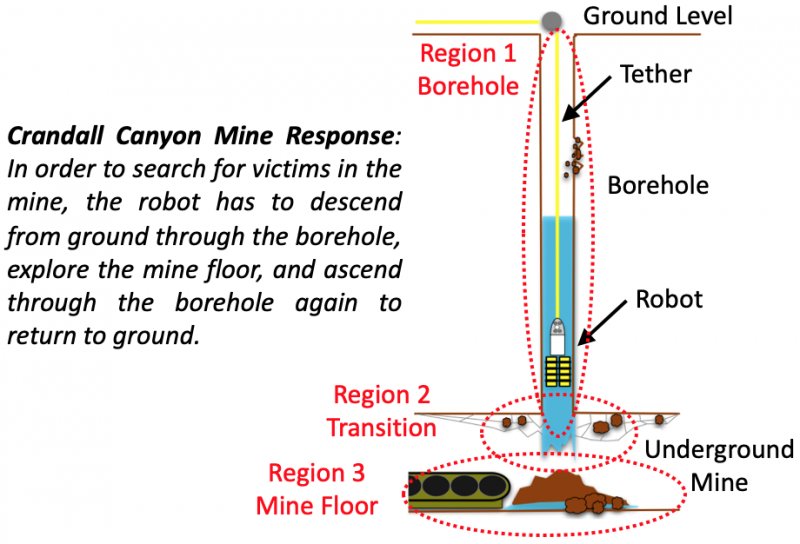
|
This project develops a formal robot motion risk reasoning framework and develops a risk-aware path planner that minimizes the proposed risk. While robots locomoting in unstructured or confined environments face a variety of risk, existing risk only focuses on collision with obstacles. Such risk is currently only addressed in ad hoc manners. Without a formal definition, ill-supported properties, e.g. additive or Markovian, are simply assumed. Relied on an incomplete and inaccurate representation of risk, risk-aware planners use ad hoc risk functions or chance constraints to minimize risk. The former inevitably has low fidelity when modeling risk, while the latter conservatively generates feasible path within a probability bound. Using propositional logic and probability theory, the proposed motion risk reasoning framework is formal. Building upon a universe of risk elements of interest, three major risk categories, i.e. locale-, action-, and traverse-dependent, are introduced. A risk-aware planner is also developed to plan minimum risk path based on the newly proposed risk framework. Results of the risk reasoning and planning are validated in physical experiments in a real-world unstructured or confined environment. With the proposed fundamental risk reasoning framework, safety of robot locomotion could be explicitly reasoned, quantified, and compared. The risk-aware planner finds safe path in terms of the newly proposed risk framework and enables more risk-aware robot behavior in unstructured or confined environments.
|
Tethered Aerial Visual Assistance

|
This project develops an autonomous tethered aerial visual assistant for robot operations in unstructured or confined environments. Robotic tele-operation in remote environments is difficult due to lack of sufficient situational awareness, mostly caused by the stationary and limited field-of-view and lack of depth perception from the robot's onboard camera. The emerging state of the practice is to use two robots, a primary and a secondary that acts as a visual assistant to overcome the perceptual limitations of the onboard sensors by providing an external viewpoint. However, problems exist when using a tele-operated visual assistant: extra manpower, manually chosen suboptimal viewpoint, and extra teamwork demand between primary and secondary operators. In this work, we use an autonomous tethered aerial visual assistant to replace the secondary robot and operator, reducing human robot ratio from 2:2 to 1:2. This visual assistant is able to autonomously navigate through unstructured or confined spaces in a risk-aware manner, while continuously maintaining good viewpoint quality to increase the primary operator's situational awareness. With the proposed co-robots team, tele-operation missions in nuclear operations, bomb squad, disaster robots, and other domains with novel tasks or highly occluded environments could benefit from reduced manpower and teamwork demand, along with improved visual assistance quality based on trustworthy risk-aware motion in cluttered environments.
|
Autonomous Marine Mass Casualty Incident Response
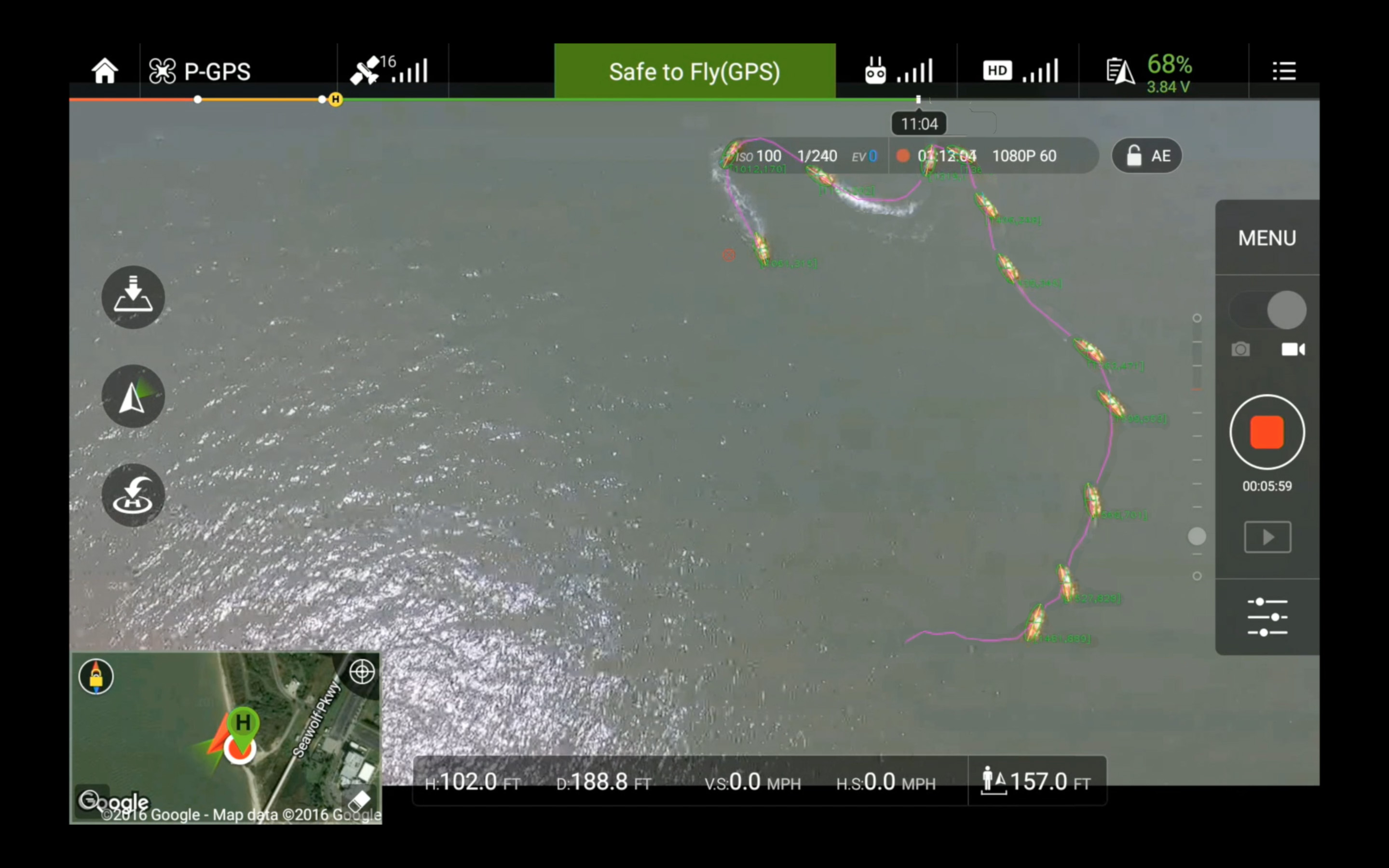
|
This project teams an Unmanned Surface Vehicle (USV) with an Unmanned Aerial Vehicle (UAV) to augment and automate marine mass casualty incident search and rescue in emergency response phase. The demand for real-time responsiveness of those missions requires fast and comprehensive situational awareness and precise operations, which are challenging to achieve because of the large area and the flat nature of the water field. The responders, drowning victims, and rescue vehicle are far apart and all located at the sea level. The long distances mean responders cannot clearly discern the rescue vehicle and victims from the surrounding water. Furthermore, being at the same elevation makes depth perception difficult. Rescue vehicle and victims at different distances from the responder will always appear to be close together. This makes it almost impossible for the responders to accurately drive the USV to the victims in time. This project uses a UAV to compensate for the lack of elevation of the responders and to automate search and rescue operations. The benefit of this system is two fold: 1) the UAV provides responders with an overhead view of the field, covers larger area than direct visual, and allows more accurate perception of the situation, and 2) it automates the rescue process so that the responders can focus on task-level needs instead of tediously driving the USV to the victims. The result of this research project has been deployed for marine mass casualty incident response in search and rescue exercises conducted by the United States Coast Guard and Galveston Fire Department during Summer Institute 2016 in Galveston, TX; Italian Coast Guard during 2016 exercise in Genoa, Italy; Brazos County Fire Department and Grimes County Emergency Management during Brazos Valley Search and Rescue Exercise 2017 in Gibbons Creek, TX; Los Angeles County Fire Department Lifeguards during 2017 exercise in Los Angeles, CA; and Department of Homeland Security during 2017 CAUSE V exercise in Bellingham, WA.
|