A new task scheduling strategy keeps user data private in distributed networks.
by Jason Wang
A new method of transmitting data could revolutionize the security of devices that we all use in our daily lives. Today, most multimedia applications utilize cloud computing, which gives users more computing power and storage by offloading their computational needs via the Internet to data servers across the globe. One problem with cloud computing is that the requested data server may be geographically far away, which could mean huge delays for the user. Distributed networks solve this problem by utilizing several data servers (called nodes) that are closer to the user’s device, whose collective computational power provides the requested service. However, privacy should be a matter of concern since users may not want the data sent to these nodes to go public.
With the new task scheduling method developed by Hengrun Zhang, a PhD student at GMU’s Department of Computer Science, distributed networks may not have to sacrifice privacy after all. In his paper presented at INFOCOM 2019, Zhang describes a novel task scheduling strategy that would keep user data private in distributed networks.
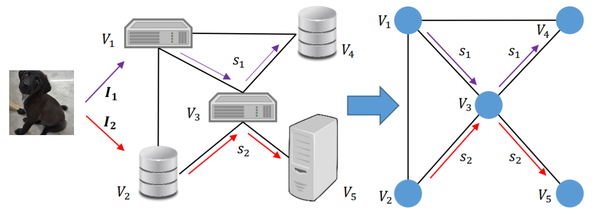
The key to Zhang’s strategy is to schedule the processes so that each node in the distributed network receives only a part of the original data. Using an image as an example, half of the image would be processed by one node, and the other half processed by a second node. This way, no node can reconstruct the original image and violate the user’s privacy. This enforced separation is accomplished through a pairwise Markov Chain.
A Markov Chain is the set of probabilities from which one state might transition to another. In this case, each node represents a state, and the task scheduler has the option to keep processing at that node or to send it to another node. The catch is that by combining every pair of nodes into one state (hence “pairwise”), this Markov Chain can define a scheduler that sends the data to pairs to uphold the privacy constraint.
While the pairwise Markov Chain accomplishes the goal of preserving privacy, there is more that can be done to improve performance. “Actually, in this first method, we did not consider too much about the throughput performance.” Zhang says. He proposed a second method called delay-based backpressure scheduling that would help further optimize the task scheduler.
Backpressure scheduling is an algorithm in queuing theory that maximizes the throughput performance of a network: the number of data packets a network can handle at a time. Essentially, it splits its operation into time slots where it queues data every time slot to minimize backlog. Zhang uses its delay-based variant to avoid delays from the last packet going through the network.
In order to test and improve his algorithm, Zhang introduced a new metric called “privacy collisions” that he defines as the number of times a data packet is forced onto a less optimal route because of the privacy constraint. According to Zhang, “if the number of privacy collisions is large enough, the scheduling scheme will suffer from a severe degradation of throughput region, which severely degrades throughput performance of the existing backpressure scheme.” This new privacy scale could become a ubiquitous tool for further network development, or even be the next research topic.
Zhang remains excited about future work on his task scheduling algorithm. He says, “In the future, we will consider cases with multiple nodes or shares, rescheduling problems, as well as networks with heterogeneous nodes.” There are many ways that attackers could breach a network, including the possibility of eavesdropping on multiple nodes. With more and more data being uploaded across the web, as well as the increasing demand for cloud computing, privacy is one thing that we could all use more of.